
A Critical Evaluation of RAG in Medicine, Decomposing the Value of Modern Recommendation Algorithms, and More!
Vol.130 for Nov 10 - Nov 16, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Practical Optimizations for LLM-Based Pairwise Reranking in Production Systems, from Capital One
Efficient End-to-End Long-Sequence Recommendation at Billion Scale, from ByteDance
A Structural Approach to Valuing Personalized Recommendations in Attention Markets, from Netflix
Integrating Structured Human Priors into Generative Recommenders, from Meta
A Fine-Grained Analysis of Retrieval-Augmented Generation in Medicine, from Kim et al.
A Quantitative Framework for Understanding Collaborative Information in Recommendation, from Zhang et al.
A Framework for Reducing Token Overhead in Agentic RAG, from Zhang et al.
A Two-Tier Framework for Optimizing Semantic Precision and Contextual Coherence in Information Retrieval, from Dell Technologies
A Unified Generative Framework for Large-Scale Advertising Recommendation, from Tencent
Universal Multilingual Text Embeddings with Llama-Embed-Nemotron-8B, from NVIDIA
[1] LLM Optimization Unlocks Real-Time Pairwise Reranking
This paper from Capital One’s AI Foundations team demonstrates how to make LLM-based pairwise reranking practical for real-time RAG systems. The authors reduce latency from 61 seconds to 0.37 seconds per query (a 166x speedup) while maintaining nearly identical performance. They achieved this through six key optimizations: switching to smaller models (FLAN-T5-XL instead of FLAN-UL2), implementing single-pass sliding window reranking focused on identifying just the top-1 document, carefully tuning the Top-K threshold for documents sent to the reranker, loading models with lower precision (bfloat16), using one-directional order inference to mitigate positional bias while halving comparisons, and constraining the model to generate only single tokens through careful prompt engineering. This paper shows that carefully designed optimization strategies can make computationally expensive pairwise reranking viable for latency-sensitive production environments where sub-second response times are critical.
📚 https://arxiv.org/abs/2511.07555
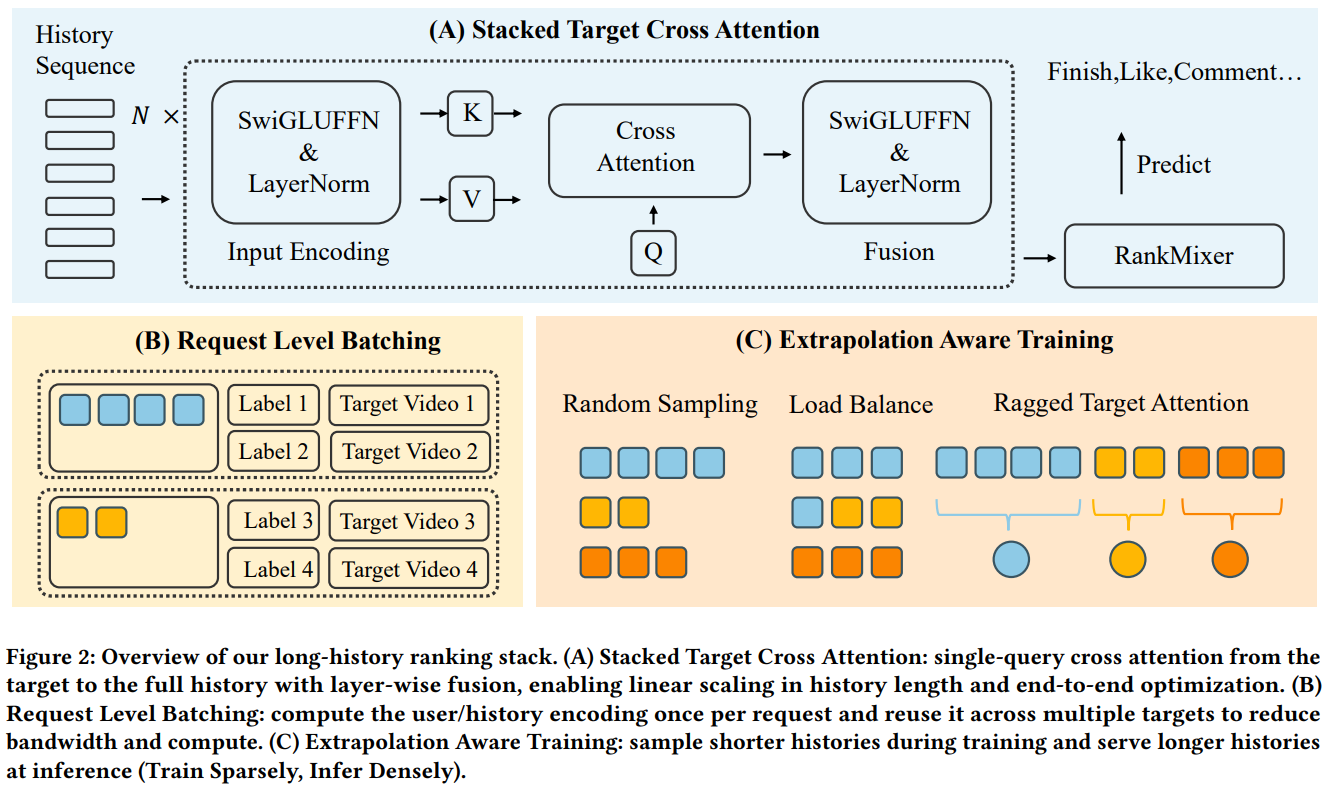
[2] Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
This paper from ByteDance addresses the challenge of scaling recommender systems to handle 10,000-length user histories in production on Douyin (the Chinese version of TikTok) while maintaining strict latency constraints. The authors introduce three key innovations: (1) Stacked Target-to-History Cross Attention (STCA), which replaces quadratic-complexity history self-attention with linear-complexity cross-attention by treating the target item as a single query attending to the full history; (2) Request Level Batching (RLB), a training strategy that computes user-side encodings once per request and reuses them across multiple candidate items, reducing bandwidth by 77-84% and improving throughput by 2.2x; and (3) a length-extrapolation training approach that trains on sequences averaging ~2k tokens but deploys on 10k-length histories at inference time, decoupling training costs from deployment context length. The system demonstrates scaling-law behavior where performance improves predictably with both sequence length and model capacity. The work shows that careful architectural choices combined with systems-level optimizations can make true end-to-end long-sequence modeling practical for billion-scale recommendation, avoiding the information loss inherent in two-stage retrieval-then-rank paradigms.
📚 https://arxiv.org/abs/2511.06077
[3] The Value of Personalized Recommendations: Evidence from Netflix
This paper from Netflix develops a discrete choice model to separately quantify the value of personalized recommendations and underlying content preferences on the Netflix platform. Using data from 2 million U.S. users and approximately 7,000 titles over 35 days in early 2025, the authors build a model that embeds recommendation-induced utility, low-rank preference heterogeneity, and flexible state dependence based on viewing history. They exploit idiosyncratic variation from Netflix’s recommendation algorithm exploration to identify these components and validate their model using experimental data that achieves strong out-of-sample performance. Their key findings reveal that replacing the current recommender system with matrix factorization or popularity-based algorithms would reduce engagement by 4% and 12% respectively, while also decreasing consumption diversity. They decompose recommendation effects into selection (51.3%), exposure (6.8%), and targeting (41.9%) components, showing that effective personalization, not merely mechanical exposure, drives most consumption increases, with mid-popularity titles benefiting most from targeting rather than broadly appealing or highly niche content. The study demonstrates that modern recommendation algorithms provide substantial value beyond earlier approaches like matrix factorization.
📚 https://arxiv.org/abs/2511.07280
[4] Don’t Waste It: Guiding Generative Recommenders with Structured Human Priors via Multi-head Decoding
This paper from Meta AI introduces a framework for integrating structured human priors (domain knowledge like item taxonomies, temporal patterns, and interaction types) directly into generative recommendation systems. Rather than relying on post-hoc adjustments or fully unsupervised learning, the method uses multi-head decoding where each adapter head specializes in modeling specific facets of user intent along interpretable dimensions (e.g., item categories, short-term vs. long-term interests, interaction modalities). The framework is backbone-agnostic and includes a hierarchical composition strategy to model complex interactions across different prior types while mitigating data sparsity for rare combinations. Evaluated on three large-scale datasets using HSTU and HLLM architectures, the approach demonstrates consistent improvements in both standard accuracy metrics (Recall, NDCG) and beyond-accuracy objectives, including diversity, novelty, and personalization.
📚 https://arxiv.org/abs/2511.10492
👨🏽💻 https://github.com/zhykoties/Multi-Head-Recommendation-with-Human-Priors
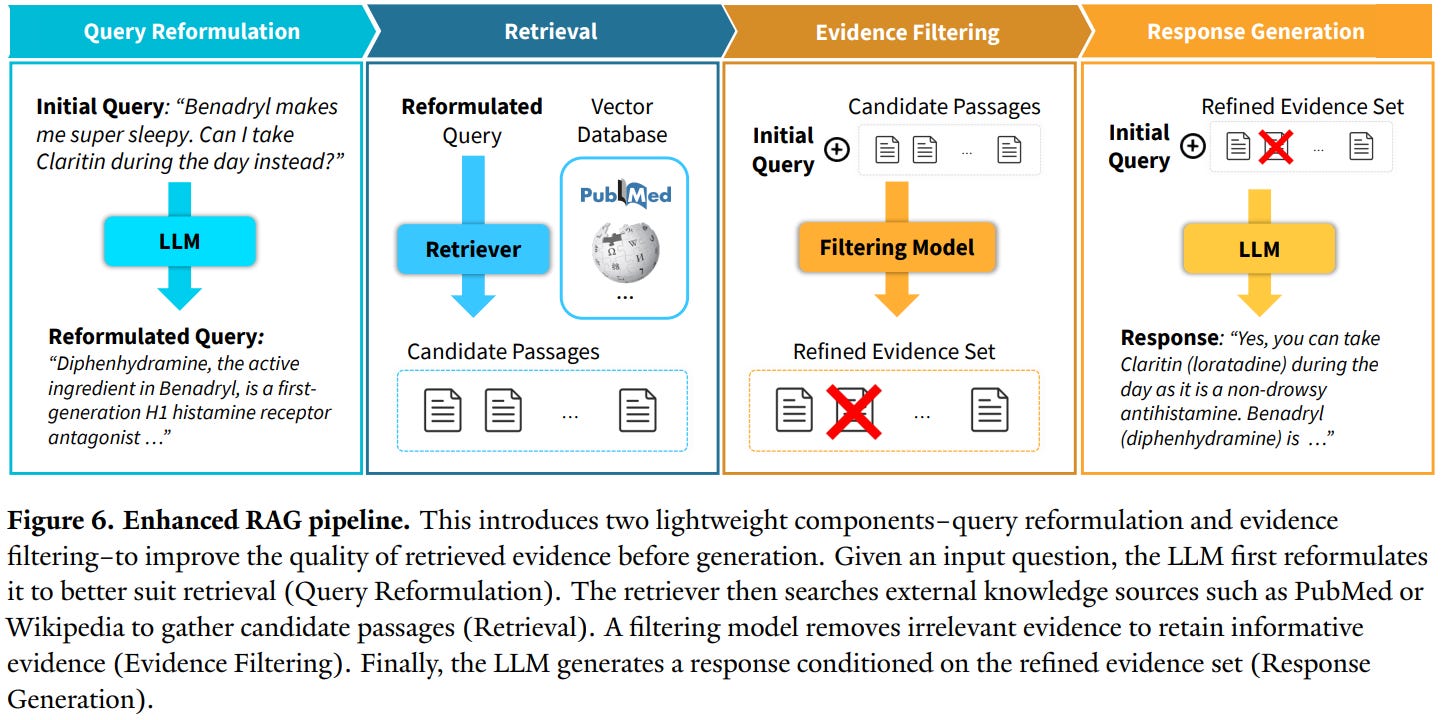
[5] Rethinking Retrieval-Augmented Generation for Medicine: A Large-Scale, Systematic Expert Evaluation and Practical Insights
This paper from Kim et al. presents a comprehensive evaluation of RAG systems in medical applications, revealing significant limitations contrary to common assumptions. Through analysis involving 18 medical experts who contributed over 80,000 annotations across 200 queries evaluated on GPT-4o and Llama-3.1-8B, the researchers systematically assessed three RAG pipeline components: evidence retrieval, evidence selection, and response generation. Their findings demonstrate that standard RAG often degrades performance rather than improving it (only 22% of retrieved passages were relevant), models struggled with evidence selection (precision 41-43%, recall 27-49%), and both factuality and completeness decreased by up to 6% and 5% respectively, compared to non-RAG baselines. The study identifies retrieval inadequacy and poor evidence selection as primary bottlenecks, with models frequently incorporating irrelevant content while missing available relevant information. To address these issues, the authors propose two practical interventions: evidence filtering to remove irrelevant passages and query reformulation to improve retrieval precision. When combined, these strategies yielded substantial improvements on challenging benchmarks. The research challenges the default application of RAG in medicine and emphasizes the necessity of stage-aware evaluation and deliberate system design for reliable clinical AI applications.
📚 https://arxiv.org/abs/2511.06738
👨🏽💻 https://github.com/Yale-BIDS-Chen-Lab/medical-rag
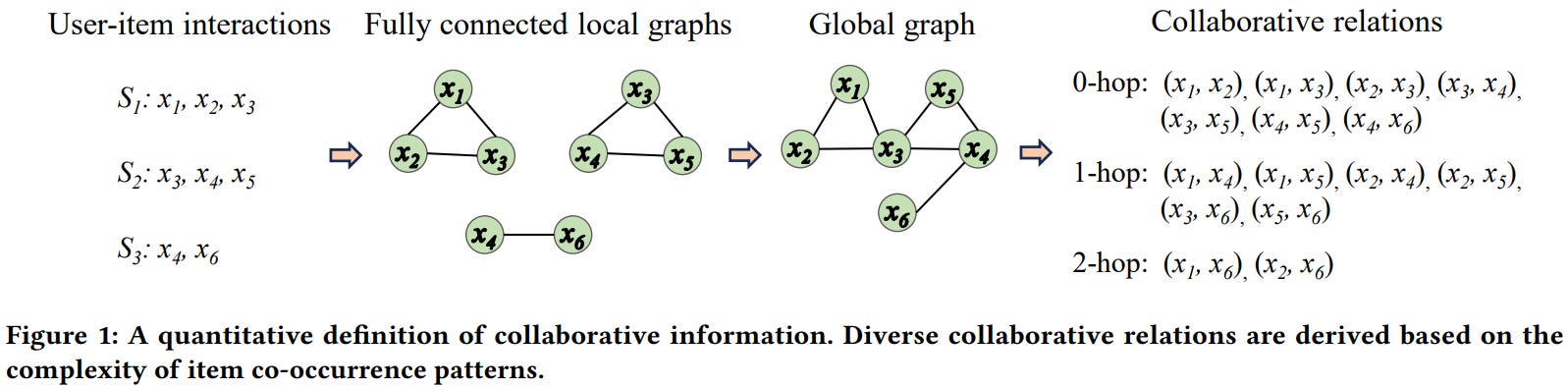
[6] Have We Really Understood Collaborative Information? An Empirical Investigation
This paper from Zhang et al. presents a systematic empirical investigation of collaborative information in recommender systems. The authors define collaborative information through item co-occurrence patterns and identify three key characteristics: transitivity, hierarchy, and redundancy. They propose categorizing collaborative relations (CR) into types based on complexity (0-hop, 1-hop, 2-hop, etc.), where 0-hop represents direct co-occurrence and higher-order relations represent increasingly complex patterns. Through experiments on six benchmark datasets using traditional methods, neural networks, and LLM-based approaches, the study reveals several critical findings: direct collaborative relations are rare but highly valuable; indirect relations dominate item interactions; and recommender systems perform significantly better on simple relations than complex ones. The research demonstrates that neural models outperform traditional techniques primarily through their ability to capture complex collaborative relations, while LLM-based methods struggle to encode collaborative knowledge from user-item interactions despite their success in other domains.
📚 https://arxiv.org/abs/2511.06905
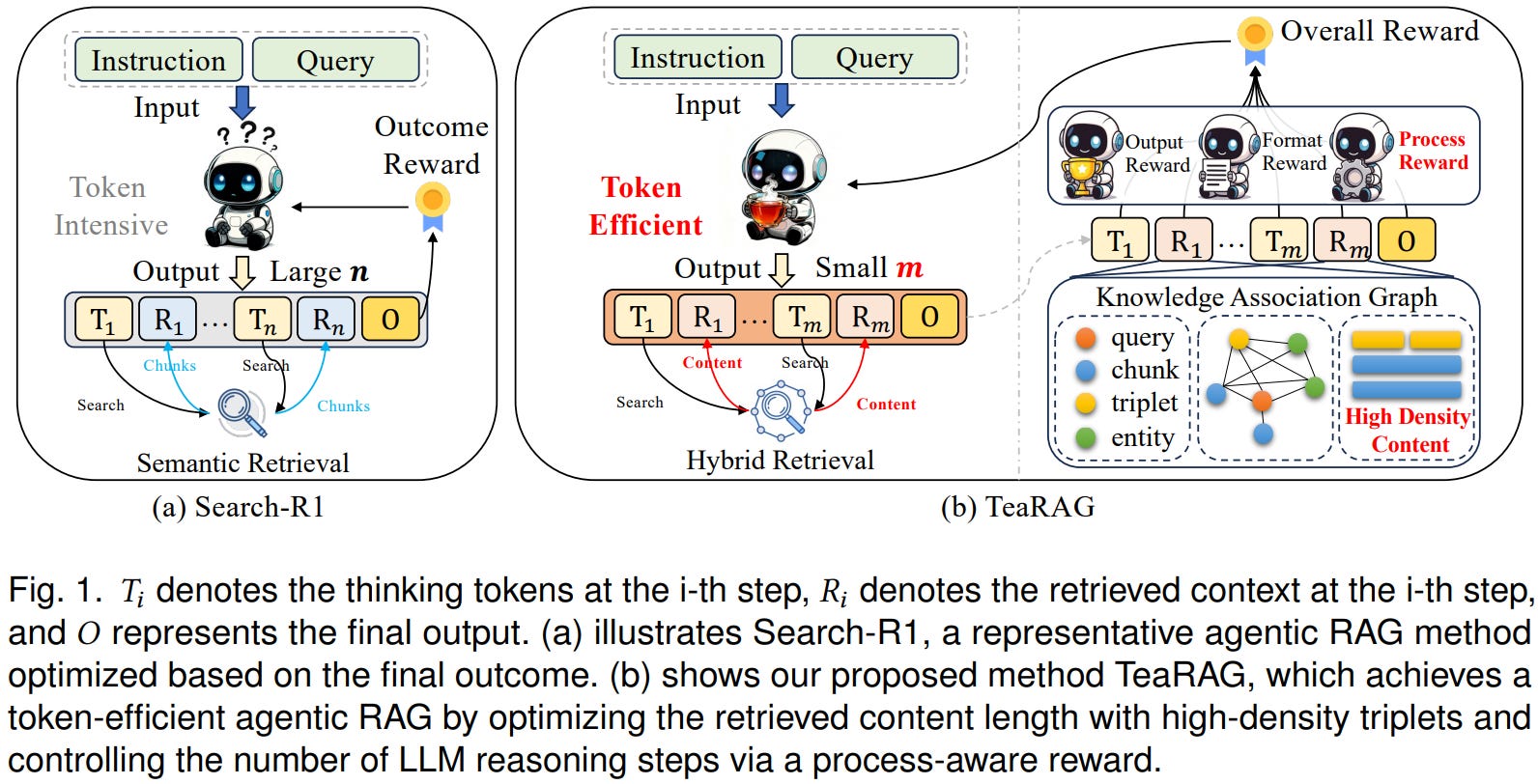
[7] TeaRAG: A Token-Efficient Agentic Retrieval-Augmented Generation Framework
This paper from Zhang et al. presents TeaRAG, a token-efficient agentic RAG framework that addresses the excessive token overhead in current agentic systems, which prioritize accuracy over efficiency through multi-round retrieval and reasoning. The framework achieves efficiency improvements through two key mechanisms: (1) compressing retrieval content by augmenting chunk-based semantic retrieval with graph retrieval using concise knowledge triplets, constructing a Knowledge Association Graph from semantic similarity and co-occurrence relationships, and applying Personalized PageRank to filter redundant information while preserving essential context; and (2) reducing reasoning steps through Iterative Process-aware Direct Preference Optimization (IP-DPO), which employs a reward function that evaluates knowledge sufficiency via knowledge matching across subquery generation, context retrieval, and summarization dimensions, while penalizing excessive reasoning steps. The training paradigm consists of supervised fine-tuning on the MuSiQue dataset to establish basic reasoning capabilities, followed by iterative DPO that separates sampling and training phases for efficient optimization. Evaluated across six QA benchmarks, TeaRAG improves average Exact Match scores by 4% on Llama3-8B-Instruct and 2% on Qwen2.5-14B-Instruct while reducing output tokens by 61% and 59% respectively.
📚 https://arxiv.org/abs/2511.05385
👨🏽💻 https://github.com/Applied-Machine-Learning-Lab/TeaRAG
[8] Search Is Not Retrieval: Decoupling Semantic Matching from Contextual Assembly in RAG
This paper from Dell Technologies presents Search-Is-Not-Retrieve (SINR), a framework that separates semantic matching from contextual assembly through a dual-layer architecture. Traditional RAG systems use uniform chunk sizes that force a tradeoff between precision (small chunks) and context (large chunks), but SINR resolves this by employing fine-grained search chunks (approximately 100-200 tokens) for accurate semantic matching and coarse-grained retrieve chunks (600-1000 tokens) for providing sufficient reasoning context. The system uses a deterministic parent mapping function that connects each search chunk to exactly one retrieve chunk, enabling the retrieval process to first identify relevant content through precise semantic search, then expand to contextually complete passages without additional computational overhead. This architecture offers several advantages: independent optimization of search precision and context quality, natural deduplication when multiple search chunks share the same parent, improved traceability from query to answer, and scalability to billions of documents with negligible mapping overhead (less than 1% of embedding storage).
📚 https://arxiv.org/abs/2511.04939
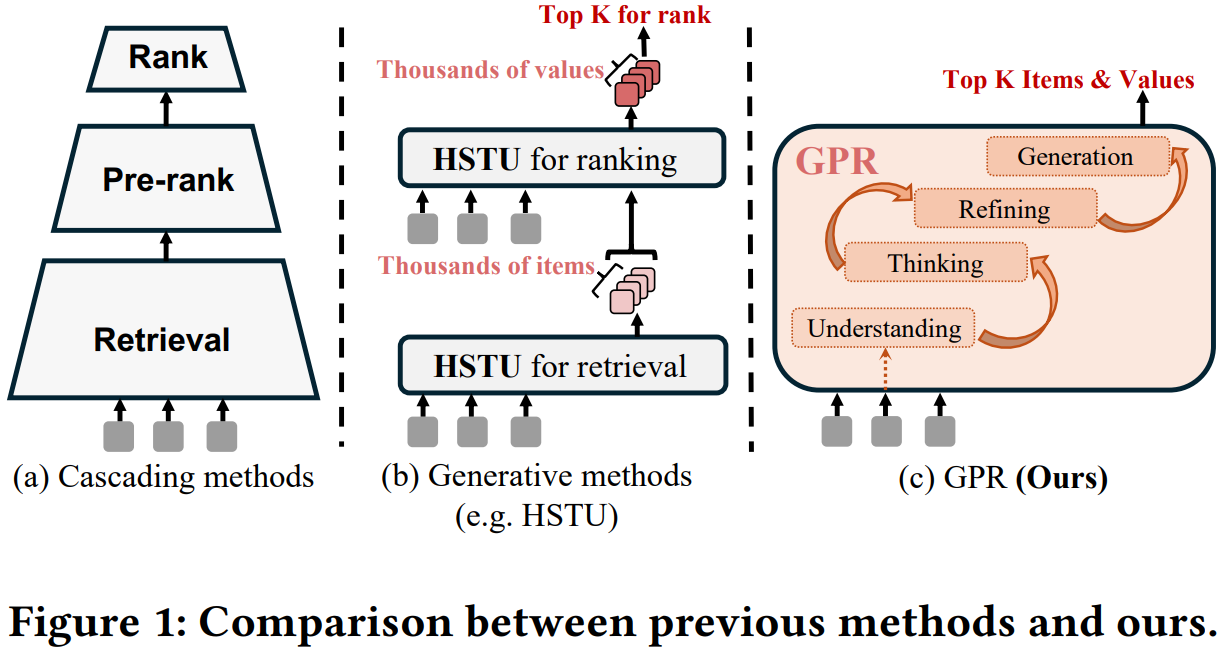
[9] GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
This paper from Tencent introduces GPR (Generative Pre-trained Recommender), an end-to-end generative framework for large-scale advertising recommendation that replaces traditional multi-stage cascading systems (retrieval-pre-ranking-ranking) with a unified one-model approach. The system addresses three key challenges: extreme data heterogeneity from mixed ad and organic content, the efficiency-flexibility trade-off in training and inference, and multi-stakeholder value optimization. GPR’s core innovations include: (1) RQ-Kmeans+, an improved tokenization method that maps heterogeneous content into a shared semantic ID space; (2) a Heterogeneous Hierarchical Decoder (HHD) architecture featuring dual decoders that separate user intent modeling from ad generation; and (3) a multi-stage training strategy combining Multi-Token Prediction, Value-Aware Fine-Tuning, and Hierarchy Enhanced Policy Optimization (HEPO). Deployed in Tencent’s Weixin Channels advertising system, GPR demonstrated significant improvements in key metrics, including GMV and CTCVR through extensive A/B testing.
📚 https://arxiv.org/abs/2511.10138
[10] Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks
This paper from NVIDIA introduces llama-embed-nemotron-8b, an open-source text embedding model that achieves state-of-the-art performance on the Multilingual Massive Text Embedding Benchmark (MMTEB) as of October 2025. Built on Llama-3.1-8B architecture with modified bidirectional attention, the model excels across retrieval, classification, and semantic similarity tasks in 250+ languages. Its training leverages a data mix of 16.1 million query-document pairs, combining 7.7 million public samples with 8.4 million synthetically generated examples from diverse open-weight LLMs. Key innovations include instruction-aware embeddings that adapt to specific use cases, a simplified contrastive loss using only hard negatives (outperforming approaches with in-batch or same-tower negatives), and model merging across six diverse checkpoints to enhance robustness. The model achieves 39,573 Borda votes on MMTEB, outperforming competitors like Gemini Embedding and Qwen3-Embedding.
📚 https://arxiv.org/abs/2511.07025
👨🏽💻 https://huggingface.co/nvidia/llama-embed-nemotron-8b
Extras: Tools
🛠️ EncouRAGe: Evaluating RAG Local, Fast, and Reliable
EncouRAGe is a Python framework designed to support the development and evaluation of RAG systems by providing a modular structure for datasets, retrieval methods, inference, and metrics. It standardizes data through an object-oriented type manifest, offers ten configurable RAG methods through a unified factory interface, and integrates local or cloud-based LLM and embedding models. The framework includes more than twenty generator, retrieval, and LLM-based evaluation metrics and supports multiple vector stores.
📝 https://arxiv.org/abs/2511.04696
👨🏽💻 https://anonymous.4open.science/r/encourage-B501/
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.