
A Unified Approach to Job Search Query Understanding, Efficient Inference for Generative Recommenders, and More!
Vol.122 for Sep 15 - Sep 21, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Scalable Cross-Entropy Loss with Negative Sampling for Industrial Recommendation Systems, from Zhelnin et al.
Unified LLM Architecture for Large-Scale Job Search Query Understanding, from LinkedIn
What News Recommendation Research Doesn't Teach About Building Real Systems, from Higley et al.
A Systematic Evaluation of Large Language Models for Cross-Lingual Information Retrieval, from LMU Munich
Interactive Two-Tower Architecture for Real-Time Candidate Filtering in Recommender Systems, from Ant Group
Efficient Inference for Generative LLM Recommenders via Hidden State Matching, from Wang et al.
A Framework for Training Embedding Models, from Scratch, from Tencent
A Comprehensive Review of Large Language Models in Document Intelligence, from Ke et al.
A Modular Analysis of LLM-Based Feature Extraction for Sequential Recommendation, from Shi et al.
Systematic Data Augmentation for Enhanced Generative Recommendation, from Lee et al.
[1] Faster and Memory-Efficient Training of Sequential Recommendation Models for Large Catalogs
This paper from Zhelnin et al. presents CCE⁻ (Cut-Cross-Entropy with negative sampling), a GPU-efficient implementation designed to address the substantial memory and computational challenges faced when training sequential recommendation models on large item catalogs. Sequential recommendation systems using transformer architectures like SASRec typically encounter memory bottlenecks due to cross-entropy loss computation, where peak memory scales with catalog size, batch size, and sequence length, for industrial datasets with millions of items. The authors develop CCE⁻ as an extension of the existing CCE method, incorporating negative sampling and gradient sparsification techniques implemented through custom Triton kernels. Their approach achieves up to 2x training acceleration and over 10x memory reduction compared to standard PyTorch implementations, while maintaining or improving model accuracy on six benchmark datasets. Through comprehensive experiments, they demonstrate that optimal performance requires balanced scaling of batch size, sequence length, and number of negative samples rather than maximizing any single parameter, and show that their memory savings can be reallocated to increase these hyperparameters for up to 30% accuracy improvements. The method provides a practical solution for industrial-scale recommendation systems requiring frequent retraining.
📚 https://arxiv.org/abs/2509.09682
👨🏽💻 https://github.com/On-Point-RND/RePlay-Accelerated
[2] Powering Job Search at Scale: LLM-Enhanced Query Understanding in Job Matching Systems
This paper from LinkedIn presents a unified LLM-enhanced query understanding framework for their job search platform, replacing traditional fragmented Named Entity Recognition (NER) models with a single LLM to improve job matching at scale. The system consists of four main components powered by a fine-tuned Qwen2.5-1.5B model: a Query Planner that routes queries into categories (criteria search, self-reference search, non-job related, or trust violations), a Query Tagger for extracting structured attributes like job titles and locations, a Query Rewriter that enriches self-referential queries with user profile information, and a Facet Suggestion module for recommending filtering options. Through multi-task instruction tuning with homogeneous batching and supervised fine-tuning, the framework achieved significant improvements in online A/B testing, while maintaining sub-600ms P95 latency and reducing system maintenance overhead by over 75% compared to the legacy multi-model architecture.
📚 https://arxiv.org/abs/2509.09690
[3] What News Recommendation Research Did (But Mostly Didn't) Teach Us About Building A News Recommender
This paper from Higley et al. presents a case study of building POPROX, a live news recommendation research platform, and reflects on the significant gaps between academic recommender systems research and the practical challenges of building real-world systems. The authors, who attempted to apply current news recommendation literature to create a platform delivering personalized newsletters to subscribers, encountered unexpected difficulties in several key areas: training recommendation models with limited user data and heterogeneous metadata that differs from public datasets, implementing user preference controls for explicit topic interests (which are rarely addressed in research despite being common in commercial systems), combining editorial curation with algorithmic personalization, and conducting longitudinal user experience evaluation through surveys. While they successfully deployed POPROX using transfer learning with the NRMS model trained on MIND dataset and developed workaround solutions for user preferences, the authors conclude that the substantial body of news recommendation research has had less real-world impact than expected, largely due to the field's focus on narrow accuracy benchmarks rather than the comprehensive functionality required for production systems. They advocate for research that treats data utilization as a first-order concern, develops models with clear affordances for system integration, recognizes that recommendation involves much more than modeling alone.
📚 https://arxiv.org/abs/2509.12361
👨🏽💻 https://github.com/CCRI-POPROX/poprox-recommender
[4] Evaluating Large Language Models for Cross-Lingual Retrieval
This paper from LMU Munich conducts a systematic evaluation of LLMs for cross-lingual information retrieval (CLIR), examining both passage-level and document-level reranking without relying entirely on machine translation. The authors evaluate multi-stage retrieval pipelines using multilingual bi-encoders (M3, mGTE, E5, RepLLaMA, NV-Embed-v2) as first-stage retrievers paired with LLM-based rerankers (RankZephyr, RankGPT variants) on CLEF 2003 and CIRAL datasets covering European and African languages. Key findings reveal that multilingual bi-encoders can outperform translation-based lexical retrieval methods, that stronger rerankers diminish the benefits of document translation, and that instruction-tuned pairwise rerankers (using Llama-3.1-8B-Instruct and Aya-101) perform competitively with specialized listwise rerankers. The study demonstrates that while reranking consistently improves retrieval performance, current state-of-the-art rerankers fall significantly short of their theoretical potential in cross-lingual settings without translation, achieving only 32-46% of possible improvements. The research also shows that document length affects reranking performance differently for listwise versus pairwise approaches, with pairwise methods being more robust to longer inputs when paired with high-quality dense retrievers.
📚 https://arxiv.org/abs/2509.14749
👨🏽💻 https://github.com/mainlp/llm-clir [not public as of 09/19]
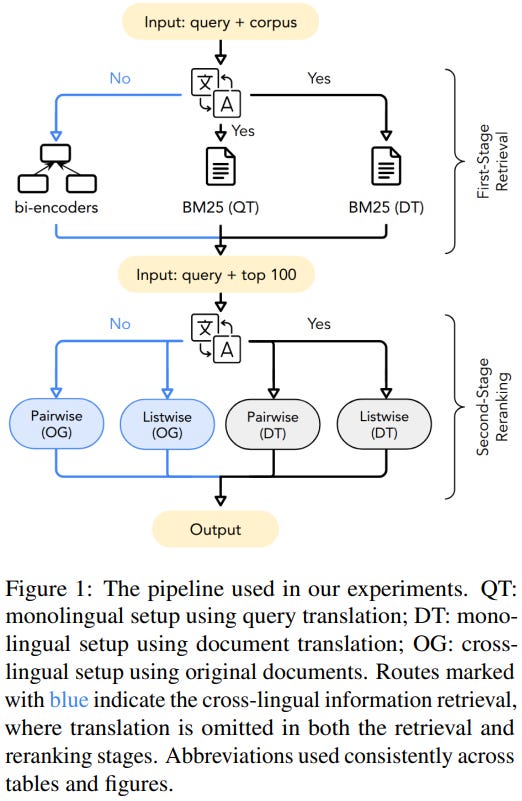
[5] A Learnable Fully Interacted Two-Tower Model for Pre-Ranking System
This paper from Ant Group introduces FIT (Fully Interacted Two-Tower Model), an architecture for pre-ranking systems in large-scale recommender systems that addresses the lack of information interaction between user and item towers until the output layer of traditional two-tower models. The authors propose two key components: the Meta Query Module (MQM), which creates a learnable item meta matrix to enable expressive early interaction between user and item features while maintaining the efficient user-item decoupling architecture, and the Lightweight Similarity Scorer (LSS), which replaces the simple dot product with row-wise and column-wise fully connected layers to capture more effective late interactions. The model successfully bridges the gap between effectiveness and efficiency in pre-ranking systems by enabling rich feature interactions through the learnable meta matrix during training while using hard queries during inference, thus preserving the computational advantages of the two-tower paradigm that are crucial for real-time candidate filtering from millions of items.
📚 https://arxiv.org/abs/2509.12948
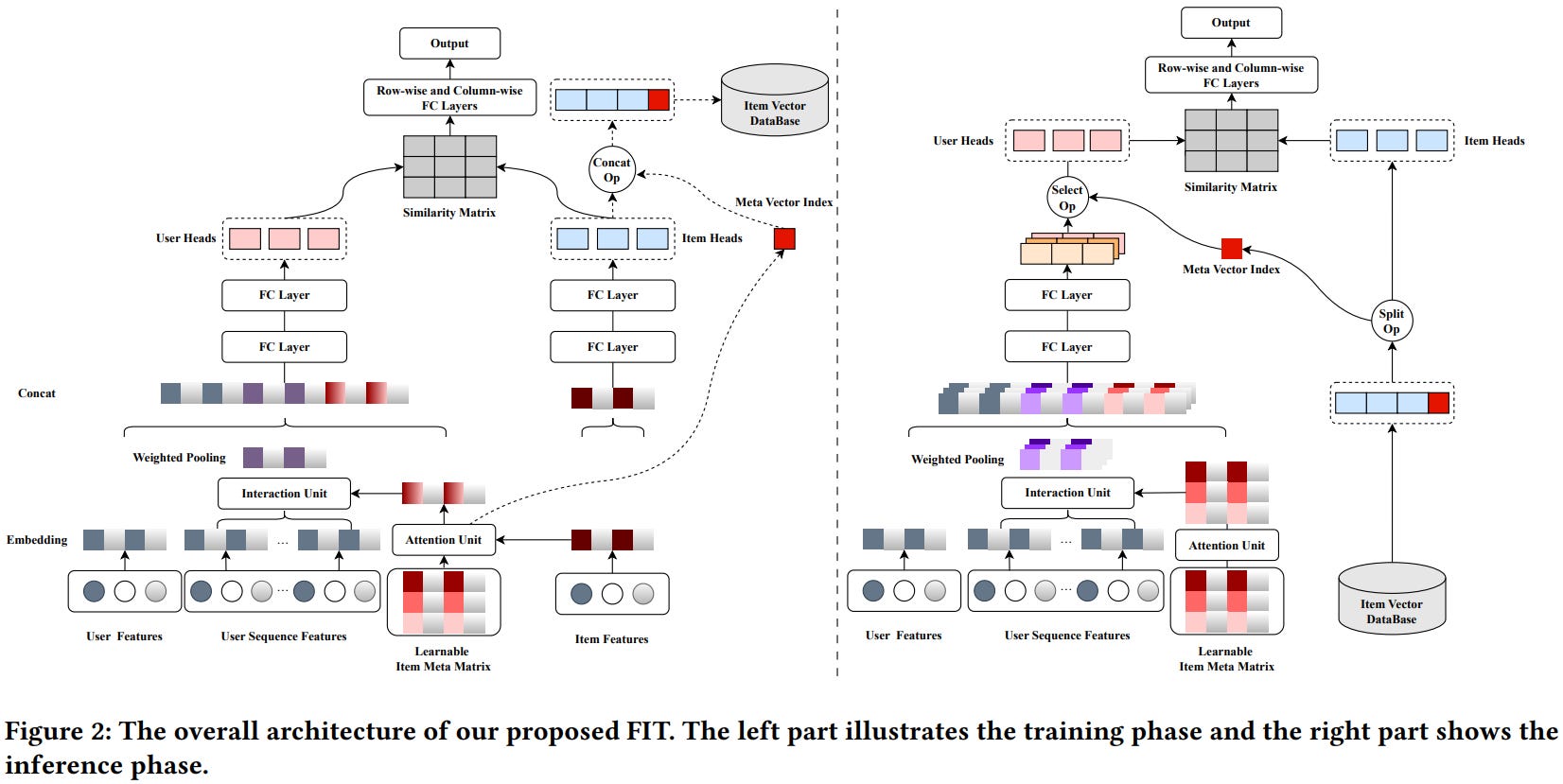
[6] Decoding in Latent Spaces for Efficient Inference in LLM-based Recommendation
This paper from Wang et al. introduces Light Latent-space Decoding (L2D), an approach to address the significant inference overhead in LLM-based recommendation systems that arises from autoregressive token-by-token generation in language space. Instead of generating item representations through slow autoregressive decoding, L2D bypasses this process by directly matching candidate items with the LLM's internal "thought" representations in latent space, using hidden states from the final layer that capture the model's internal understanding of user preferences. The method constructs a memory module storing hidden state-item pairs from training data, then generates candidate item representations through either global aggregation (averaging all associated hidden states) or local aggregation (using only the most relevant samples), before performing efficient similarity matching with test samples' hidden states using L2 distance. Experiments demonstrate that L2D achieves 10x speedup compared to traditional language-space decoding while maintaining or improving recommendation performance. This approach effectively preserves the benefits of generative LLM training while enabling practical deployment through efficient latent-space inference.
📚 https://arxiv.org/abs/2509.11524
[7] Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings
This paper from Tencent introduces Conan-embedding-v2, a 1.4 billion parameter LLM trained from scratch specifically for text embedding tasks. The researchers tackle two critical issues: the data gap between general LLM corpora and embedding-specific datasets, and the training gap between causal masking used in autoregressive language modeling versus bidirectional masking needed for sentence-level embeddings. Their approach includes incorporating news and multilingual data during pretraining, implementing a novel "soft mask" mechanism that gradually transitions from causal to bidirectional attention during training, creating a cross-lingual retrieval dataset spanning 26 languages to improve multilingual representation alignment, and developing dynamic hard negative mining that adaptively updates challenging negative examples throughout training. The model achieves state-of-the-art performance on both English and Chinese MTEB benchmarks while maintaining computational efficiency with only 1.4B parameters, demonstrating that training embedding models from scratch with specialized techniques can outperform larger models that rely on LoRA fine-tuning of existing LLMs.
📚 https://arxiv.org/abs/2509.12892
[8] Large Language Models in Document Intelligence: A Comprehensive Survey, Recent Advances, Challenges and Future Trends
This comprehensive survey from Ke et al. examines the impact of LLMs on document intelligence, analyzing approximately 300 papers published between 2021 and mid-2025 to provide an in-depth overview of how LLMs have revolutionized document processing and understanding. The authors categorize document intelligence solutions into two primary paradigms: pipeline-based approaches that decompose tasks into sequential modules (OCR, layout analysis, content recognition) and end-to-end approaches using multimodal LLMs that directly process document images. The survey systematically explores key technical advances including document parsing methods, fine-tuning strategies for document-specific LLMs, retrieval-augmented generation (RAG) frameworks for handling long documents, and techniques for managing extended context windows through positional encoding improvements and attention mechanism optimizations. Additionally, the paper addresses challenges in document intelligence such as complex layout interpretation, high-resolution image processing, multi-page document understanding, tabular data reasoning, and multimodal information integrations.
📚 https://dl.acm.org/doi/10.1145/3768156
[9] What Matters in LLM-Based Feature Extractor for Recommender? A Systematic Analysis of Prompts, Models, and Adaptation
This paper from Shi et al. introduces RecXplore, a systematic, modular framework for analyzing LLM-based feature extractors in recommender systems. The researchers decompose the LLM-as-feature-extractor pipeline into four distinct modules: data processing (converting item attributes to text), feature extraction (using LLMs to generate semantic embeddings), feature adaptation (transforming high-dimensional LLM outputs), and sequential modeling (feeding adapted features to recommendation models like SASRec). Through experiments, they evaluate different design choices within each module independently rather than proposing new techniques. Their key findings reveal that simple attribute concatenation outperforms complex prompt engineering, mean pooling works best for feature aggregation, a two-stage fine-tuning approach (continued pre-training followed by supervised fine-tuning) produces superior representations, and a hybrid PCA-MoE adapter proves most effective for feature adaptation. When traditional ID embeddings are combined with sufficiently rich semantic embeddings, direct replacement emerges as the optimal integration strategy.
📚 https://arxiv.org/abs/2509.14979
[10] Sequential Data Augmentation for Generative Recommendation
This paper from Lee et al. addresses a fundamental yet underexplored aspect of generative recommendation systems: how training data is constructed from user interaction histories through data augmentation strategies. The authors demonstrate that commonly used approaches like Last-Target, Multi-Target, and Slide-Window create substantially different training distributions, leading to performance variations of up to 783.7% in NDCG@10 across the same models. Through systematic analysis, they show that model performance correlates with alignment between training and test target distributions, as well as the balance between "alignment" (similarity to positive training examples) and "discrimination" (dissimilarity to negative examples) in input-target distributions. To address these findings, they propose GenPAS (Generalized and Principled Augmentation for Sequences), a unified framework that decomposes data augmentation into three controllable sampling steps: sequence sampling, target sampling, and input sampling, each governed by bias parameters. The framework encompasses existing strategies as special cases while enabling systematic exploration of the augmentation space through a principled parameter search that filters configurations based on target distribution alignment and input-target trade-offs.
📚 https://arxiv.org/abs/2509.13648
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.