
Understanding Stability in Modern Vector Databases, A Generative Paradigm Shift for Click-Through Rate Prediction, and More!
Vol.135 for Dec 15 - Dec 21, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Stability Analysis of Multi-Vector, Filtered, and Sparse Neural Embedding Retrieval, from Lakshman et al.
RecGPT-V2’s Agentic Framework for Industrial-Scale Recommendation, from Alibaba
Enhancing Graph Collaborative Filtering through Frequency Signal Scaling and Space Flipping, from Liu et al.
A High-Throughput Serving System for Generative Recommendation with Large-Scale Beam Search, from Sun et al.
A Structured Memory Architecture for Preference-Consistent AI Agents, from Vectorize
Fast and Accurate Sequential Recommendation through Hardware-Friendly Temporal Modeling, from Yi et al.
A Supervised Generative Framework for CTR Prediction Models, from Tencent
Mitigating Attention Noise in Generative Recommendation with Focused Attention, from Xiao et al.
Why LLM-Supervised Embeddings Beat LLM Rerankers in Cold-Start Scenarios, from NEC Corporation
Aligning Dual-Tower Representations Through Symmetric Training and Consistent Indexing, from JD[.com]
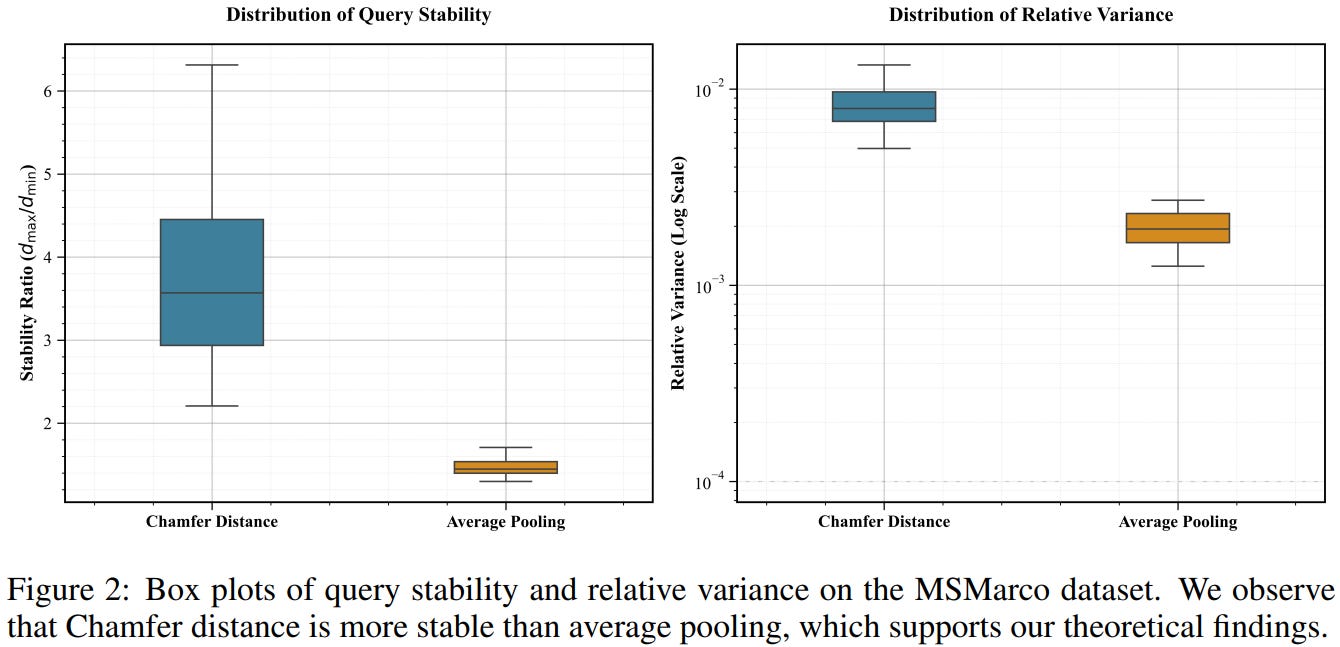
[1] Breaking the Curse of Dimensionality: On the Stability of Modern Vector Retrieval
This paper from Lakshman et al. investigates why modern high-dimensional vector retrieval systems succeed despite classical theory predicting they should suffer from the “curse of dimensionality,” where distances between points become indistinguishable. The authors extend foundational stability theory, i.e., the property that small query perturbations don’t drastically alter nearest neighbors, to three practical retrieval settings: (1) multi-vector search, proving that ColBERT’s Chamfer distance preserves stability when the underlying single-vector problem is strongly stable, while average pooling may not; (2) filtered vector search, demonstrating that sufficiently large penalties for filter mismatches can induce stability even when base search is unstable; and (3) sparse vector search, where they formalize “concentration of importance” (mass concentrated in few dimensions) and introduce “overlap of importance” (shared important dimensions between queries and documents), proving both properties together ensure stability. Through theoretical analysis using relative variance criteria and experiments on synthetic and real datasets (including ColBERT, SPLADE embeddings, and standard IR benchmarks), they validate that these conditions explain why modern neural embeddings enable efficient sub-linear search algorithms, providing actionable guidance for practitioners designing retrieval systems and embedding models.
📚 https://arxiv.org/abs/2512.12458
👨🏽💻 https://github.com/vihan-lakshman/ann-stability-theory
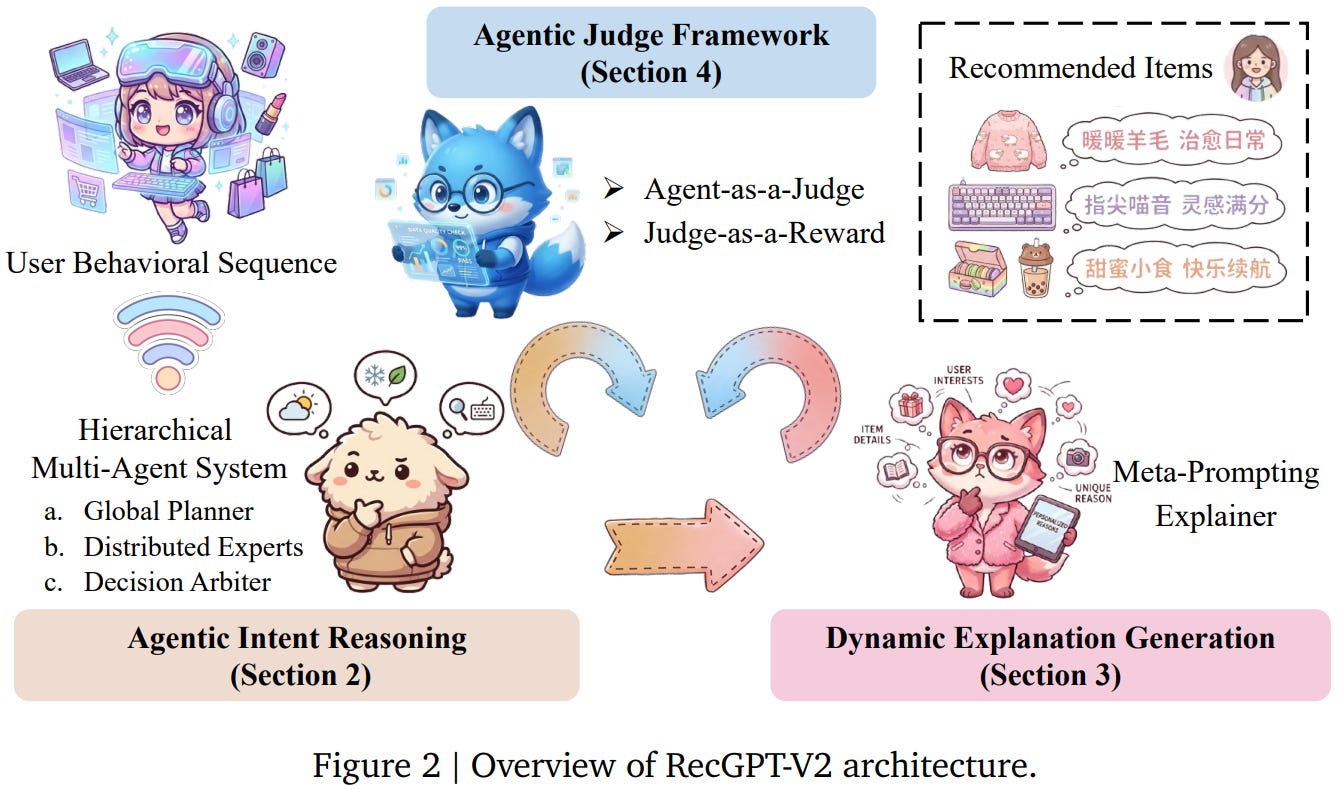
[2] RecGPT-V2 Technical Report
This paper from Alibaba presents RecGPT-V2, an advancement in LLM-powered recommender systems, addressing four critical limitations of its predecessor RecGPT-V1: computational inefficiency, insufficient explanation diversity, limited generalization, and simplistic evaluation methods. The system introduces a Hierarchical Multi-Agent System that restructures intent reasoning through coordinated collaboration (Global Planner → Distributed Experts → Decision Arbiter), combined with a Hybrid Representation Inference that compresses user-behavior contexts from 32K to 11K tokens, achieving 60% reduction in GPU consumption while improving exclusive recall from 9.39% to 10.99%. To enhance explanation quality, RecGPT-V2 employs Meta-Prompting for dynamic, contextually adaptive explanation generation. The evaluation framework advances from outcome-focused LLM-as-a-Judge to process-oriented Agent-as-a-Judge, decomposing quality assessment into multi-dimensional sub-evaluators. Deployed at scale on Taobao’s “Guess What You Like” feature, RecGPT-V2 demonstrated substantial improvements over RecGPT-V1: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER, establishing both technical feasibility and commercial viability of LLM-powered intent reasoning in industrial recommender systems.
📚 https://arxiv.org/abs/2512.14503
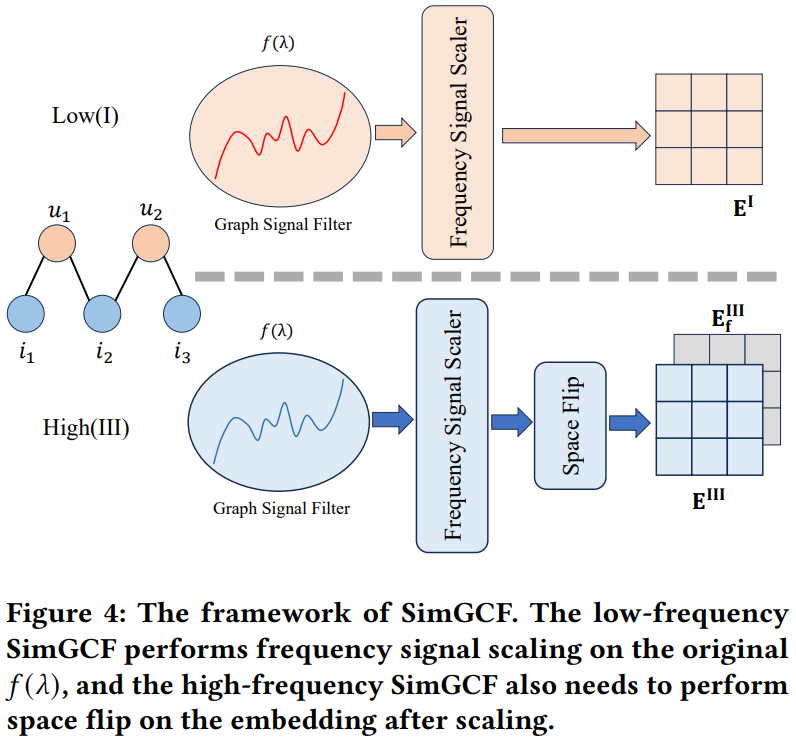
[3] How Do Graph Signals Affect Recommendation: Unveiling the Mystery of Low and High-Frequency Graph Signals
This paper from Liu et al. investigates how low-frequency and high-frequency graph signals affect recommendation systems by examining spectral graph neural networks (GNNs). The authors theoretically prove that low-frequency and high-frequency graph signals with the same absolute waveform value are equivalent in recommendation tasks, as both influence performance by smoothing similarities between user-item pairs. They identify a critical limitation that current graph embedding methods can only capture half of the graph signal characteristics, specifically failing to represent signals where the filter function f(λ) < 0. To address this, they propose two key contributions: (1) a “space flip” method that restores hidden high-frequency features by negating embeddings, and (2) a “frequency signal scaler” - a plug-and-play module using learnable monomial bases to fine-tune the graph signal filter function’s waveform. Their proposed model, SimGCF, demonstrates that either low-frequency or high-frequency signals alone can achieve effective recommendations when properly processed. Extensive experiments on four benchmark datasets validate their theoretical findings and show that SimGCF outperforms state-of-the-art baselines while maintaining computational efficiency comparable to LightGCN.
📚 https://arxiv.org/abs/2512.15744
👨🏽💻 https://github.com/mojosey/SimGCF
[4] xGR: Efficient Generative Recommendation Serving at Scale
This paper from Sun et al. presents xGR, a specialized serving system for generative recommendation (GR) that addresses the challenges of deploying LLM-based recommendation systems at scale. Unlike conversational LLMs that generate long responses from short prompts, GR systems process long user behavior sequences (hundreds to thousands of tokens) while producing short, fixed-length outputs representing item recommendations. The authors identify three critical bottlenecks: (1) redundant KV cache loading across beam sequences that share identical prompt contexts, (2) costly memory operations from beam search requiring large beam widths (≥128) to ensure recommendation diversity, and (3) extremely strict latency requirements (P99 ≤200ms) under high concurrency. xGR introduces three integrated solutions: xAttention separates shared and unshared KV cache with staged computation allocation across hardware units; xBeam implements early sorting termination and mask-based filtering to handle the vast item space efficiently while ensuring only valid items are recommended; and xSchedule employs a three-tier hierarchy enabling multi-level pipeline parallelism and multi-stream execution. Experiments on real-world datasets demonstrate that xGR achieves at least 3.49x throughput improvement over state-of-the-art baselines while maintaining strict SLO requirements, even at peak traffic of tens of thousands of requests per second.
📚 https://arxiv.org/abs/2512.11529

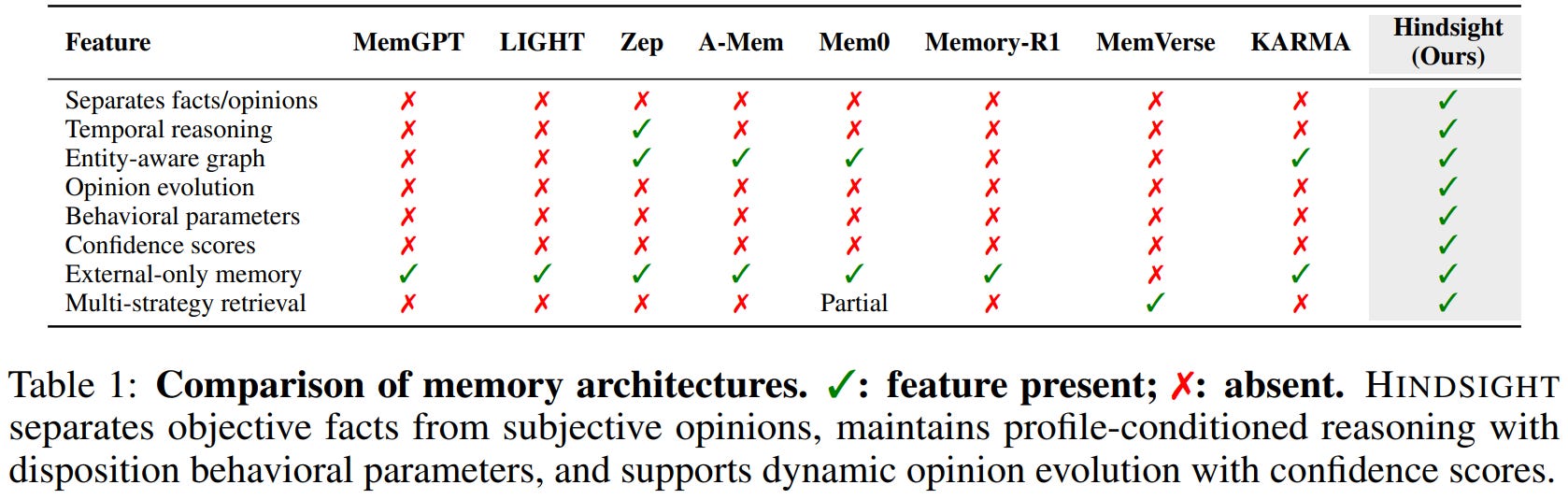
[5] Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects
This paper from Vectorize presents HINDSIGHT, a novel memory architecture for AI agents that addresses how current systems handle long-term memory by organizing information into four distinct networks: world facts, personal experiences, subjective opinions, and synthesized entity observations, and exposing three core operations: retain (storing structured information with temporal and entity metadata), recall (multi-strategy retrieval combining semantic search, keywords, graph traversal, and temporal filtering), and reflect (generating preference-conditioned responses while forming and updating beliefs). The system comprises TEMPR, which builds a temporal entity-aware memory graph through LLM-powered narrative fact extraction and maintains sophisticated retrieval capabilities, and CARA, which implements configurable behavioral profiles (skepticism, literalism, empathy) to produce consistent reasoning across sessions while maintaining an explicit opinion network that evolves with new evidence. On LongMemEval and LoCoMo benchmarks testing multi-session conversational memory, HINDSIGHT with an open-source 20B parameter model achieves 83.6% and 85.67% accuracy, respectively, demonstrating that structured memory architecture rather than raw model scale drives performance on long-horizon reasoning tasks requiring epistemic clarity, temporal awareness, and preference consistency.
📚 https://arxiv.org/abs/2512.12818
👨🏽💻 https://github.com/vectorize-io/hindsight
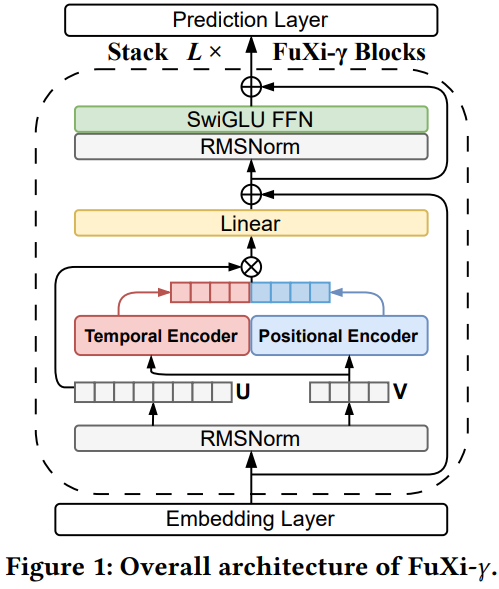
[6] FuXi-γ: Efficient Sequential Recommendation with Exponential-Power Temporal Encoder and Diagonal-Sparse Positional Mechanism
This paper from Yi et al. presents FuXi-γ, a sequential recommendation framework that introduces two key innovations: an exponential-power temporal encoder and a diagonal-sparse positional mechanism. The temporal encoder, inspired by the Ebbinghaus forgetting curve, uses a tunable exponential decay function to model how user interests fade over time, enabling flexible capture of both short-term and long-term preferences through continuous memory access and pure matrix operations, achieving up to 11× speedup over bucket-based approaches. The diagonal-sparse positional mechanism prunes low-contribution attention blocks using a diagonal-sliding strategy guided by the persymmetry of Toeplitz matrices, reducing positional attention overhead by 74.56% while maintaining recommendation quality. On a large-scale industrial music dataset, FuXi-γ achieves improvement over strong autoregressive baselines, while accelerating training by up to 4.74× and inference by up to 6.18×, making it particularly effective for long-sequence recommendation scenarios where both accuracy and computational efficiency are critical.
📚 https://arxiv.org/abs/2512.12740
👨🏽💻 https://github.com/Yeedzhi/FuXi-gamma
[7] From Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models
This paper from Tencent introduces a Supervised Feature Generation (SFG) framework that reconceptualizes CTR prediction by shifting from a discriminative “feature interaction” paradigm to a generative “feature generation” paradigm. Traditional CTR models suffer from embedding dimensional collapse and information redundancy due to their reliance on explicit interactions between raw ID embeddings, whereas SFG addresses these limitations through an encoder-decoder architecture that treats feature co-occurrence as the inherent data structure, using all features as both source and target in an “All-Predict-All” framework. The encoder transforms input features into a latent space using field-wise single-layer non-linear MLPs, while the decoder maps these representations back to generate all original features, with the entire system optimized using supervised signals (click/no-click) rather than self-supervised losses typical of generative models. This framework demonstrates remarkable versatility by reformulating various existing CTR models (FM, DeepFM, xDeepFM, DCN V2) under the generative paradigm, achieving an average of 0.272% AUC improvement and 0.435% log-loss reduction across multiple datasets with minimal computational overhead (3.14% increase in computation time, 1.45% in memory). The approach effectively mitigates dimensional collapse by producing more balanced embedding spaces and reduces information redundancy by generating decorrelated representations, with deployment on Tencent’s advertising platform yielding a 2.68% GMV lift, one of their largest revenue improvements in 2024.
📚 https://arxiv.org/abs/2512.14041
👨🏽💻 https://github.com/USTC-StarTeam/GE4Rec
[8] FAIR: Focused Attention Is All You Need for Generative Recommendation
This paper from Xiao et al. presents FAIR (Focused Attention Is All You Need for Generative Recommendation), a transformer-based generative recommendation system. The paper proposes three interconnected mechanisms to mitigate attention noise caused by discretizing items into long code sequences. First, a focused attention mechanism learns two separate sets of query and key matrices, computing their difference to suppress irrelevant context while amplifying relevant signals. Second, a noise-robustness objective enforces consistency between clean and perturbed inputs (via random masking or substitution) using triplet loss, improving resilience to noisy tokens. Third, a mutual information maximization task employs contrastive learning (InfoNCE) to identify contexts most informative for next-item prediction, guiding the model to focus on predictive dependencies rather than spurious correlations. Unlike prior generative methods that use only four codes per item, FAIR effectively handles significantly longer code sequences (L=32) through non-autoregressive generation with multi-token prediction.
📚 https://arxiv.org/abs/2512.11254
[9] Are Large Language Models Really Effective for Training-Free Cold-Start Recommendation?
This paper from NEC Corporation challenges the prevailing assumption that LLMs are the most effective approach for training-free cold-start recommendation, where no task-specific training data is available and target users have zero or minimal interaction history. Through systematic experiments, the authors directly compare LLM-based rerankers (GPT-4.1, Qwen3-8B) against text embedding models (TEMs) like Qwen3-Embedding-8B and gte-Qwen2-7B-Instruct under identical conditions. The results demonstrate that modern TEMs, particularly those trained with LLM supervision on synthetic data, consistently outperform direct LLM reranking across both narrow cold-start (zero interactions, profile-only) and broad cold-start (few interactions) settings. This superiority persists even when varying the number of user interactions or candidate items, and extends to cross-domain scenarios. The user-level error analysis reveals that LLMs achieved higher scores for fewer than 25% of users in most datasets, indicating their weakness is systematic rather than user-specific. Hybrid methods applying LLM-based query expansion to TEMs showed mixed results, with benefits primarily for weaker baseline models. These findings indicate that LLM supervision is most effective when used to pretrain embeddings rather than for direct inference, contradicting the widely-held belief that direct LLM ranking is essential for training-free environments.
📚 https://arxiv.org/abs/2512.13001
[10] A Simple and Effective Framework for Symmetric Consistent Indexing in Large-Scale Dense Retrieval
This paper from JD[.com] addresses inconsistencies in dual-tower dense retrieval systems that queries and items are encoded through separate neural networks, which causes representational space misalignment and retrieval index inconsistencies, degrading performance especially on long-tail queries and in semantic ID generation for generative recommendation systems. The authors propose SCI (Symmetric Consistent Indexing), a framework comprising two components: (1) SymmAligner, which uses an input-swapping mechanism to feed queries through the item encoder and vice versa, applying symmetric contrastive loss to unify the dual-tower representation space without adding parameters, and (2) Consistent Indexing (CI), which redesigns the retrieval architecture by using query-tower embeddings to build coarse-level cluster structures while leveraging both towers for fine-grained quantization, maintaining consistency from training through inference. The framework provides theoretical guarantees through lemmas establishing gradient linear independence, representation alignment, and anisotropy reduction. Validated on MS MARCO and a billion-scale e-commerce dataset, SCI achieves substantial improvements while remaining lightweight and deployment-friendly, requiring only additional forward passes during training and remaining fully compatible with standard ANN libraries for production-scale systems.
📚 https://arxiv.org/abs/2512.13074
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.