
Training-Free Text Embeddings from Frozen LLMs, Scalable Relevance Labeling for Enterprise Search, and More!
Vol.138 for Jan 05 - Jan 11, 2026

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Leveraging Internal KV States for Training-Free LLM Embeddings, from HKUST
JEPA-Based Finetuning for Language-Invariant BERT Embeddings, from Brown University
Distilling Enterprise Search Relevance Labelers into Small Language Models, from Microsoft
Scaling Sequential Recommendation via History Compression with Learnable Tokens, from Meta
Efficient Multivector Reranking through Sparse Retrieval, from Martinico et al.
Explicit Cross-modal Calibration for Robust Omni-modal Embeddings, from Chen et al.
Process Reward Models for Mitigating Semantic Drift in Generative Recommendation, from Kuaishou
Unified Multimodal Retrieval with Qwen3-VL, from Alibaba
Combining Tree Search with Large Language Models for E-Commerce Query Categorization, from eBay
Enabling ID Embedding Transfer Across Domains Through Semantic Graph Construction, from Chen et al.
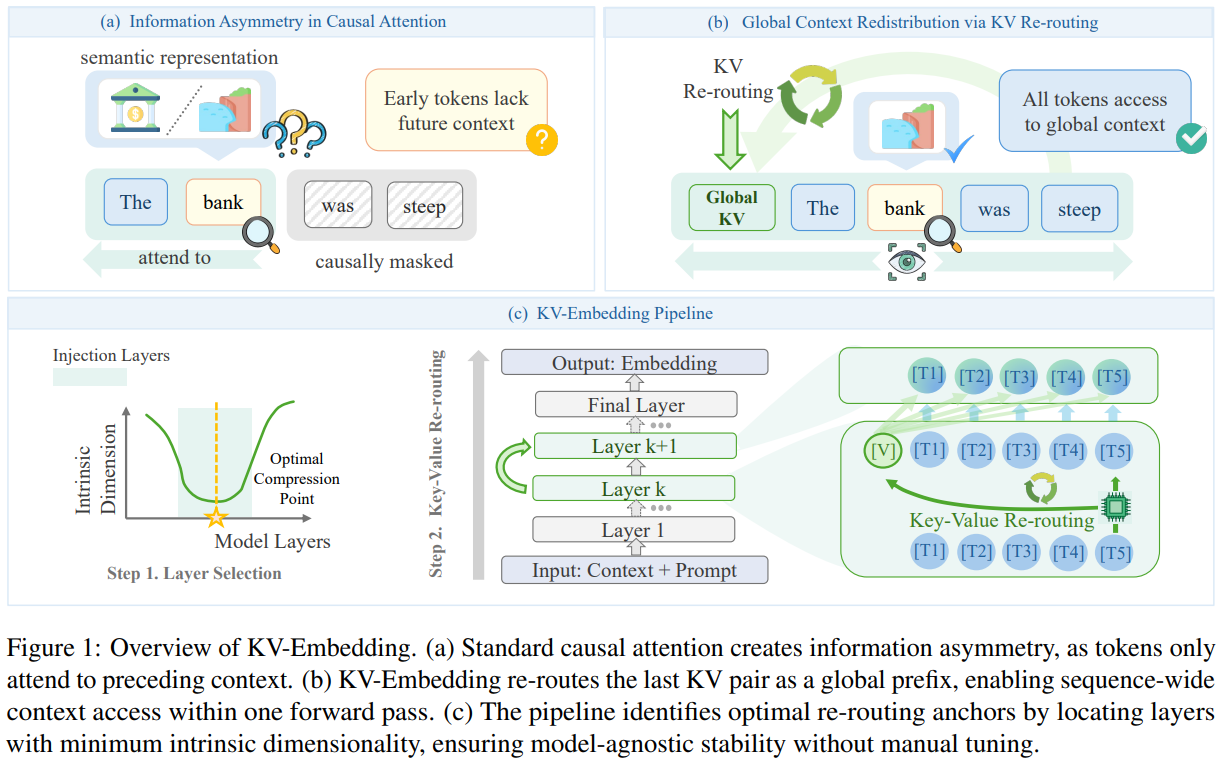
[1] KV-Embedding: Training-free Text Embedding via Internal KV Re-routing in Decoder-only LLMs
This paper from HKUST presents KV-Embedding, a training-free framework for extracting text embeddings from decoder-only LLMs that addresses two limitations of causal attention: early tokens cannot access subsequent context (information asymmetry), and the final token is biased toward next-token prediction rather than semantic compression. The method works by extracting the key-value states of the final token at selected layers, which naturally encode a compressed view of the entire sequence due to causal attention’s accumulation pattern, and prepending them as a virtual prefix, allowing all tokens to attend to this global summary within a single forward pass. To determine which layers should receive this KV re-routing, the authors use intrinsic dimensionality analysis to identify layers where representations exhibit maximal semantic compression (minimum ID), avoiding interference with shallow feature extraction or late-layer prediction heads. Combined with a compression-oriented prompt template, this approach achieves state-of-the-art results among training-free methods on MTEB benchmarks across Qwen3-4B, Mistral-7B, and Llama-3.1-8B backbones, outperforming alternatives like Echo (which doubles sequence length through repetition) and token prepending (which uses out-of-vocabulary tokens) by up to 10%.
📚 https://arxiv.org/abs/2601.01046
[2] BERT-JEPA: Reorganizing CLS Embeddings for Language-Invariant Semantics
This paper from Brown University introduces BERT-JEPA (BEPA), a finetuning framework that combines standard masked language modeling with a JEPA-style alignment objective to transform the notoriously collapsed [CLS] embedding space of BERT-style models into a language-invariant “thought space.” The method works by packing two semantically equivalent sentences (either in the same language or different languages) into a single input, running the standard MLM loss to preserve linguistic capabilities, and then performing two separate forward passes where each sentence is masked in turn to extract their respective [CLS] representations, which are aligned using InfoNCE loss. This approach addresses a well-documented problem where BERT’s [CLS] token produces collapsed embeddings with uniformly high cosine similarities regardless of semantic relatedness. The authors demonstrate through PCA analysis that BEPA-finetuned models distribute variance across more principal components (34% in the first component vs. 47-78% for baselines), and t-SNE visualizations show that language-specific clustering disappears in favor of semantically-organized overlap across languages.
📚 https://arxiv.org/abs/2601.00366
👨🏽💻 https://anonymous.4open.science/r/bert-jepa-translation-3EB8
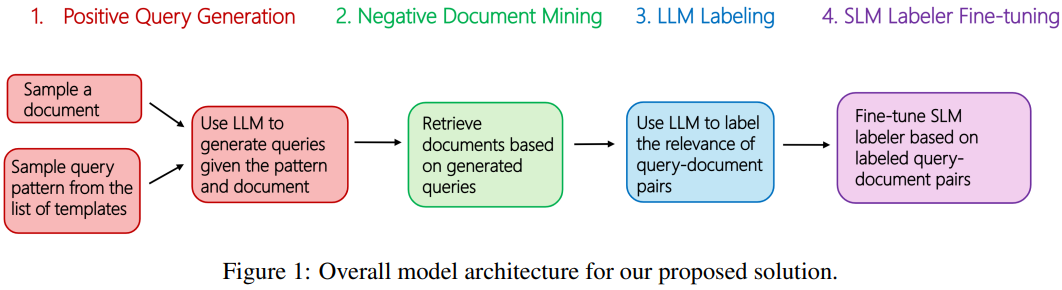
[3] Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
This paper from Microsoft addresses the challenge of relevance labeling in enterprise search, a domain that differs significantly from web search due to ambiguous, context-dependent queries that rely on organizational knowledge rather than general semantics. The authors propose a synthetic data generation pipeline that fine-tunes Phi-3.5 Mini Instruct (a small language model) to perform relevance labeling at scale without requiring expensive human annotations or LLM inference. The pipeline works in four stages: generating positive queries from enterprise documents using GPT-4o with metadata-based templates, mining hard negatives via BM25 retrieval, obtaining relevance labels (0-4 scale) from GPT-4o, and fine-tuning the SLM on the resulting triplets along with public datasets for improved generalization. Evaluated on 923 human-annotated enterprise query-document pairs, the fine-tuned SLM achieves NDCG of 0.953 and pairwise accuracy of 63.81%, slightly outperforming GPT-4o (0.944 NDCG, 62.58% accuracy) while delivering 17× higher throughput (873 RPM on a single A100) and 19× lower cost.
📚 https://arxiv.org/abs/2601.03211
[4] Efficient Sequential Recommendation for Long Term User Interest Via Personalization
This paper from Meta tackles the computational bottleneck of transformer-based sequential recommendation systems when processing long user interaction histories, a setting where performance scales with sequence length but costs grow quadratically. The authors propose “personalized experts,” a method that compresses older segments of a user’s interaction history into a small number of learnable tokens (as few as 1-4), which are then concatenated with recent interactions for next-item prediction. The approach works by dividing the user interaction history into segments, appending learnable tokens after each segment (except the last), and using a modified attention mask that restricts items to attending only within their segment plus all preceding learnable tokens; during inference, only the activations of these learnable tokens need to be cached (via KV cache), dramatically reducing computation. Evaluated with HSTU and HLLM models, the method matches or slightly exceeds the performance of baselines using full 1280-event sequences while processing only 256 recent events plus compressed tokens, achieving over 11% inference cost reduction with negligible training overhead (<5%).
📚 https://arxiv.org/abs/2601.03479
👨🏽💻 https://github.com/facebookresearch/PerSRec
[5] Multivector Reranking in the Era of Strong First-Stage Retrievers
This paper from Martinico et al. examines the efficiency limitations of current multivector retrieval systems that use token-level “gather-and-refine” strategies, where candidate documents are selected based on individual token embeddings before full MaxSim scoring. Through reproducibility experiments on MS MARCO and LoTTE datasets, the authors demonstrate that this token-level gathering is inherently inefficient, requiring searches over indexes an order of magnitude larger than document counts, and often fails to surface the most relevant documents. Their proposed alternative replaces token-level gathering entirely with learned sparse retrieval (specifically SPLADE) as a first-stage retriever, treating multivector scoring purely as a reranking step over just 20-50 candidates. The paper shows SPLADE achieves substantially higher recall than BM25 at equivalent cutoffs, enabling this smaller candidate set without sacrificing quality. To address the query encoding bottleneck in this dual-encoder setup, they integrate inference-free LSR methods (Li-LSR) that use precomputed lookup tables instead of neural query encoding. The complete pipeline achieves 10-24× faster retrieval than state-of-the-art multivector systems at comparable or superior effectiveness, with the authors providing a public implementation in Rust using kANNolo and Seismic as retrieval engines.
📚 https://arxiv.org/abs/2601.05200
👨🏽💻 https://anonymous.4open.science/r/MultivecRerank-47F9/
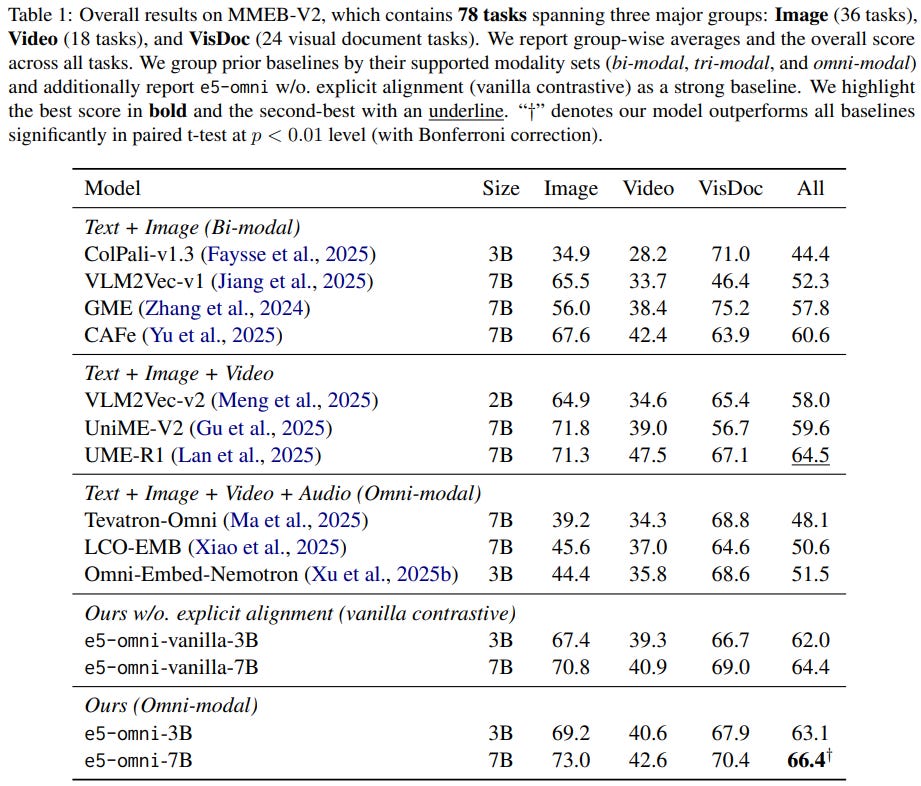
[6] e5-omni: Explicit Cross-modal Alignment for Omni-modal Embeddings
This paper from Chen et al. addresses three fundamental problems that arise when training omni-modal embedding models (handling text, images, audio, and video in a shared space) using vision-language model backbones:
Modality-dependent similarity sharpness that creates inconsistent score scales.
Negative hardness imbalance, where mixed-modality batches cause many negatives to become trivially easy and uninformative.
Geometric drift from mismatched first- and second-order statistics across modalities that destabilizes rankings.
The authors propose e5-omni, a lightweight training recipe that keeps the VLM backbone architecture unchanged while adding three explicit alignment components:
Modality-aware temperature calibration using learnable per-modality scaling vectors to normalize logit sharpness across different modality compositions.
A controllable negative curriculum that progressively masks easy negatives combined with debiased contrastive learning (DCL) to down-weight potential false negatives introduced by hard-negative selection.
Batch whitening with CORAL-style covariance regularization to align second-order geometry between query and target embeddings.
Trained on heterogeneous data spanning text-only, text-image, text-video, text-audio, and visual-document pairs using Qwen2.5-Omni as the backbone with LoRA fine-tuning, e5-omni-7B achieves 66.4 on MMEB-V2 (significantly outperforming prior omni-modal baselines like UME-R1 at 64.5) and 37.7 Recall@1 on AudioCaps text-audio retrieval.
📚 https://arxiv.org/abs/2601.03666
🤗 https://huggingface.co/Haon-Chen/e5-omni-7B
[7] PROMISE: Process Reward Models Unlock Test-Time Scaling Laws in Generative Recommendations
This paper from Kuaishou introduces PROMISE, a framework that addresses “Semantic Drift” in generative recommendation systems, a problem where errors in early tokens during hierarchical Semantic ID generation cascade irreversibly, pushing recommendations into wrong semantic subspaces (e.g., from “Electronics” to “Home Appliances”). Drawing parallels to how Process Reward Models (PRMs) improve chain-of-thought reasoning in LLMs, the authors propose a lightweight path-level PRM that provides dense, step-by-step supervision during the coarse-to-fine generation of Semantic IDs, trained jointly with the generative backbone using InfoNCE loss on both positive paths and uniformly sampled negative paths. The key insight is that while the generative model suffers from exposure bias (trained via teacher forcing but tested autoregressively), the PRM learns to discriminate good from bad trajectories by seeing both. At inference time, a PRM-guided beam search expands candidates to K⁺ (e.g., 4000-6000) then prunes back to K′ (e.g., 1000) based on PRM scores, enabling test-time scaling where increased inference compute improves performance without decoder overhead.
📚 https://arxiv.org/abs/2601.04674
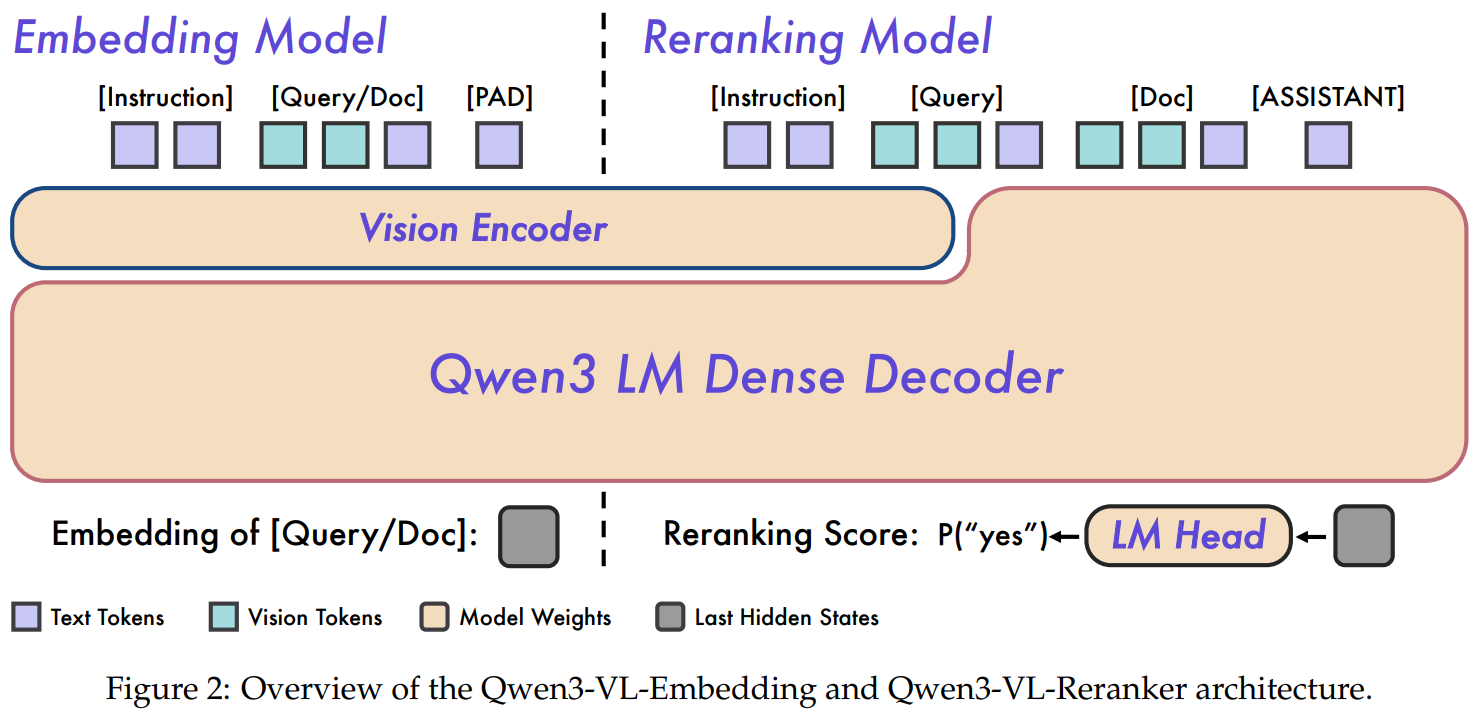
[8] Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
This technical report from Alibaba presents Qwen3-VL-Embedding and Qwen3-VL-Reranker, a pair of multimodal retrieval models built on the Qwen3-VL vision-language foundation model, released in 2B and 8B parameter sizes. The embedding model uses a bi-encoder architecture to map text, images, visual documents, and video into a unified representation space, while the reranker employs a cross-encoder that performs deep cross-attention between query-document pairs for fine-grained relevance scoring (outputting P("yes") as the relevance score). Training follows a three-stage pipeline: (1) contrastive pre-training on 300M synthesized multimodal samples using InfoNCE loss, (2) multi-task contrastive learning on 40M curated samples with task-specific losses, and (3) knowledge distillation from the reranker into the embedding model, followed by model merging to balance retrieval versus classification/QA performance. Key practical features include Matryoshka Representation Learning for flexible embedding dimensions without retraining, quantization-aware training via Learned Step Size Quantization for int8 deployment, 32K token context length, and support for 30+ languages. On MMEB-V2, Qwen3-VL-Embedding-8B achieves 77.8 overall (SOTA as of January 2026), with particularly strong results on image (80.1), video (67.1), and visual document (82.4) domains; the 8B reranker further improves retrieval tasks by 4.1 points over the 2B variant.
📚 https://arxiv.org/abs/2601.04720
👨🏽💻 https://github.com/QwenLM/Qwen3-VL-Embedding
🤗 https://huggingface.co/collections/Qwen/qwen3-vl-reranker
[9] A Chain-of-Thought Approach to Semantic Query Categorization in e-Commerce Taxonomies
This paper from eBay presents a Chain-of-Thought Breadth-First-Search (CoT BFS) method for mapping e-commerce search queries to relevant leaf categories in hierarchical product taxonomies (a core problem for search relevance and inventory targeting). The approach navigates the taxonomy tree from root to leaf by having an LLM (Mixtral-8x7B) score the semantic relevance of child categories at each level (1-10 scale), pruning branches that fall below dynamically computed thresholds based on normalized score distributions, and continuing until leaf nodes are reached. Validation against human judgments shows LLM scoring approximates human relevance assessment well, and CoT BFS substantially outperforms a k-NN embedding baseline. The method supports context injection (e.g., accessory intent or brand origin) to steer categorization appropriately, and can identify taxonomy gaps by analyzing queries that yield empty predictions at high thresholds. For production scalability to millions of queries, the authors propose hybrid approaches combining k-NN pre-filtering with LLM scoring, either at each tree level or directly on candidate leaf categories.
📚 https://arxiv.org/abs/2601.00510
[10] TextBridgeGNN: Pre-training Graph Neural Network for Cross-Domain Recommendation via Text-Guided Transfer
This paper from Chen et al. introduces TextBridgeGNN, which addresses a fundamental limitation of graph-based recommender systems: ID embeddings that capture collaborative filtering signals are domain-specific and cannot transfer across domains with independent ID spaces. The paper proposes a pre-training and fine-tuning framework that uses textual information as a semantic bridge to connect otherwise isolated domains. During pre-training on multiple source domains, a hierarchical message-passing mechanism operates at two levels: domain-specific subgraph propagation captures local interaction patterns while a global graph (constructed by linking nodes with high text-embedding similarity across domains) enables cross-domain knowledge diffusion; ID embeddings and LLM-derived text features are fused via lightweight adapters. During fine-tuning, semantic edges are established between source and target domain nodes based on text similarity, allowing the pre-trained ID embeddings and graph structure knowledge to transfer to new users/items through graph propagation.
📚 https://arxiv.org/abs/2601.02366
👨🏽💻 https://anonymous.4open.science/r/txtbrgnn-96C2
Extras: Tools
🛠️ RAGVUE: A Diagnostic View for Explainable and Automated Evaluation of Retrieval-Augmented Generation
RAGVUE is a reference-free evaluation tool designed to analyze RAG pipelines in a more diagnostic and transparent manner. It evaluates RAG systems by decomposing performance into retrieval quality, answer relevance and completeness, claim-level faithfulness to retrieved evidence, and judge calibration, rather than collapsing behavior into a single aggregate score. Each metric produces structured explanations to make evaluation outcomes interpretable.
📝 https://arxiv.org/abs/2601.04196
👨🏽💻 https://github.com/KeerthanaMurugaraj/RAGVue
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.