


Towards Agentic RAG with Deep Reasoning, A Foundation Model for User Activity Sequences at Pinterest, and More!
Vol.113 for Jul 14 - Jul 20, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
A Survey of RAG-Reasoning Systems in Large Language Models, from Li et al.
A Foundation Model for Billion-Scale User Activity Sequence Understanding, from Pinterest
Encoder vs Decoder: A Controlled Comparison of Language Model Architectures, from Weller et al.
An Empirical Study of Contrastive Learning and Knowledge Distillation in Cross-Encoder Reranking, from Xu et al.
A Corrected Importance Sampling Approach for Large-Scale Retrieval, from Yandex
Analyzing Retrieval Quality in Agentic RAG through Query Performance Prediction, from the University of Glasgow
Bridging Offline-Online Evaluation in Recommender Systems, from Wilm et al.
Item-Centric Exploration for Cold-Start Problem Resolution, from Google
Semantic Similarity-Guided Diffusion for Enhanced Sequential Recommendation, from Sejong University
A Unified Framework for Conversational Dense Retrieval and Response Generation, from Mo et al.
[1] Towards Agentic RAG with Deep Reasoning: A Survey of RAG-Reasoning Systems in LLMs
This survey paper from Li et al. examines the evolution of RAG systems from simple retrieval-then-generation approaches to sophisticated "Synergized RAG-Reasoning" frameworks that dynamically interleave search and reasoning processes. The authors categorize existing work into three paradigms: Reasoning-Enhanced RAG (using multi-step reasoning to improve retrieval, integration, and generation stages), RAG-Enhanced Reasoning (leveraging external knowledge to ground reasoning processes), and Synergized RAG-Reasoning systems where agentic LLMs iteratively combine retrieval and reasoning through chain-based, tree-based, or graph-based workflows with single or multi-agent orchestration. The paper identifies key limitations of static retrieval-then-reasoning approaches, including inadequate retrieval alignment with reasoning needs, constrained reasoning depth when facing conflicting evidence, and insufficient system adaptability for complex tasks requiring iterative feedback.
📚 https://arxiv.org/abs/2507.09477
👨🏽💻 https://github.com/DavidZWZ/Awesome-RAG-Reasoning

[2] PinFM: Foundation Model for User Activity Sequences at a Billion-scale Visual Discovery Platform
This paper from Pinterest presents PinFM, a 20-billion parameter foundational model designed to understand user activity sequences across multiple recommender applications at Pinterest's billion-scale visual discovery platform. The authors employ a pretraining-and-fine-tuning approach where they first pretrain a transformer model on extensive user activity data using modified next-token prediction objectives (including next token, multi-token, and future-token losses), then fine-tune it for specific downstream applications like Home Feed and Related Items ranking. To address the computational challenges of deploying such large models in production systems that must score millions of items per second, they developed the Deduplicated Cross-Attention Transformer (DCAT) which achieves 600% throughput improvement by leveraging the fact that there are significantly fewer unique user sequences than candidates to be scored. The model incorporates various techniques to handle cold-start items, including candidate item randomization and item-age dependent dropout, and uses int4 quantization for efficient serving of large embedding tables.
📚 https://arxiv.org/abs/2507.12704

[3] Seq vs Seq: An Open Suite of Paired Encoders and Decoders
This paper from Weller et al. introduces ETTIN, a suite of paired encoder-only and decoder-only language models ranging from 17M to 1B parameters, all trained on identical data (up to 2T tokens) using the same architectural configurations and training recipe to enable fair comparison between the two paradigms. The researchers found that their models achieve state-of-the-art performance in both categories among open-data models, with encoders excelling at classification and retrieval tasks while decoders perform better on generative tasks. Crucially, they demonstrate that cross-objective training (continuing to train decoders with masked language modeling or encoders with causal language modeling) does not close the performance gap between architectures, with a 400M encoder outperforming a 1B decoder on classification tasks and vice versa for generation.
📚 https://arxiv.org/abs/2507.11412
👨🏽💻 https://github.com/JHU-CLSP/ettin-encoder-vs-decoder
[4] Distillation versus Contrastive Learning: How to Train Your Rerankers
This paper from Xu et al. presents a comprehensive empirical comparison of two primary training strategies for cross-encoder text rerankers: contrastive learning (CL) and knowledge distillation (KD). The authors trained rerankers of varying sizes (0.5B to 7B parameters) and architectures (Transformer and Recurrent) using both methods on the same MS MARCO dataset, with a 7B Qwen2.5 model trained via contrastive learning serving as the teacher for distillation experiments. Their results demonstrate that knowledge distillation consistently outperforms contrastive learning for both in-domain and out-of-domain ranking tasks when the student model is smaller than the teacher, with improvements observed across different model sizes and architectures. However, they found that distilling from a teacher of the same capacity (7B to 7B) does not provide the same advantages, particularly for out-of-domain generalization, suggesting inherent limitations when student capacity approaches teacher capacity. The study also confirms that both training strategies exhibit clear scaling trends, with performance improving as model size increases.
📚 https://arxiv.org/abs/2507.08336
[5] Correcting the LogQ Correction: Revisiting Sampled Softmax for Large-Scale Retrieval
This paper from Yandex addresses a subtle but important flaw in the widely-used logQ correction technique for training two-tower neural networks in large-scale recommender systems. The authors identify that the standard logQ correction, which uses importance sampling to mitigate bias from in-batch negative sampling, incorrectly treats the positive item as if it were Monte Carlo sampled from the same proposal distribution as the negatives, when in reality the positive item is deterministically present with probability 1. They propose a refined correction formula that explicitly accounts for this distinction, introducing an interpretable sample weight reflecting the model's uncertainty, specifically, the probability of misclassifying the positive item under current parameters. Their improved method removes the positive item from the softmax denominator during training and applies importance sampling only to the negative terms, while using the model's confidence to weight the loss appropriately.
📚 https://arxiv.org/abs/2507.09331
👨🏽💻 https://github.com/NonameUntitled/logq/
[6] Am I on the Right Track? What Can Predicted Query Performance Tell Us about the Search Behaviour of Agentic RAG
This paper from the University of Glasgow investigates the application of Query Performance Prediction (QPP) techniques to understand the search behavior of Agentic RAG systems, specifically examining Search-R1 and R1-Searcher models that autonomously decide when to invoke retrieval during reasoning. The researchers conducted experiments using three different retrievers (BM25, MonoT5, and E5) on the Natural Questions dataset and applied various QPP methods to estimate the quality of intermediate queries generated during the reasoning process. Their findings reveal that more effective retrievers lead to shorter reasoning processes and higher answer quality, with a moderate negative correlation between iteration count and answer quality. The QPP estimates show a consistent decreasing trend as reasoning iterations progress, suggesting that retrieval quality deteriorates over time, and they found weak but positive correlations between first-iteration QPP estimates and final answer quality. The study demonstrates that QPP can serve as a useful signal for predicting answer quality in Agentic RAG systems, though the correlations are weaker than those typically observed in traditional retrieval tasks.
📚 https://arxiv.org/abs/2507.10411
[7] Identifying Offline Metrics that Predict Online Impact: A Pragmatic Strategy for Real-World Recommender Systems
This paper from Wilm et al. introduces a pragmatic strategy for identifying offline metrics that reliably predict online performance in recommender systems by leveraging Pareto front approximation techniques. The authors address the challenge of bridging the gap between offline evaluation metrics and real-world online KPIs, which is essential for effective recommender system optimization in industry settings. Their approach enables simultaneous testing of multiple offline metrics through a single scalable model that can serve different preference vectors, eliminating the need to deploy multiple model variants. The method is validated through a large-scale online experiment on the OTTO e-commerce platform involving 26.5 million impressions across session-based recommender systems. The study introduces a novel "order density" (OD@20) metric that estimates post-click conversion rates and demonstrates significant correlations between offline metrics and online performance: Recall@20 predicts click-through rates, OD@20 predicts conversion rates, and their product (Recall@20 × OD@20) predicts units sold.
📚 https://arxiv.org/abs/2507.09566
👨🏽💻 https://github.com/otto-de/MultiTRON
[8] Item-centric Exploration for Cold Start Problem
This paper from Google addresses the cold-start problem in recommender systems by proposing an item-centric approach that shifts focus from finding "the best item for a user" to identifying "the best users for an item." The authors argue that traditional user-centric systems can lead to suboptimal audience targeting for new items, particularly problematic in large-scale environments with rapidly expanding inventories where long-tail items may never find their ideal audiences. Their solution implements an item-centric filtering control within an existing exploration system that uses a Bayesian model with Beta distributions to assess whether a user's predicted satisfaction probability significantly exceeds an item's intrinsic quality threshold. The approach strategically prevents showing items to "wrong" audiences by modeling each item's satisfaction rate as a Beta distribution that converges toward its true intrinsic rate as more interaction data accumulates.
📚 https://arxiv.org/abs/2507.09423

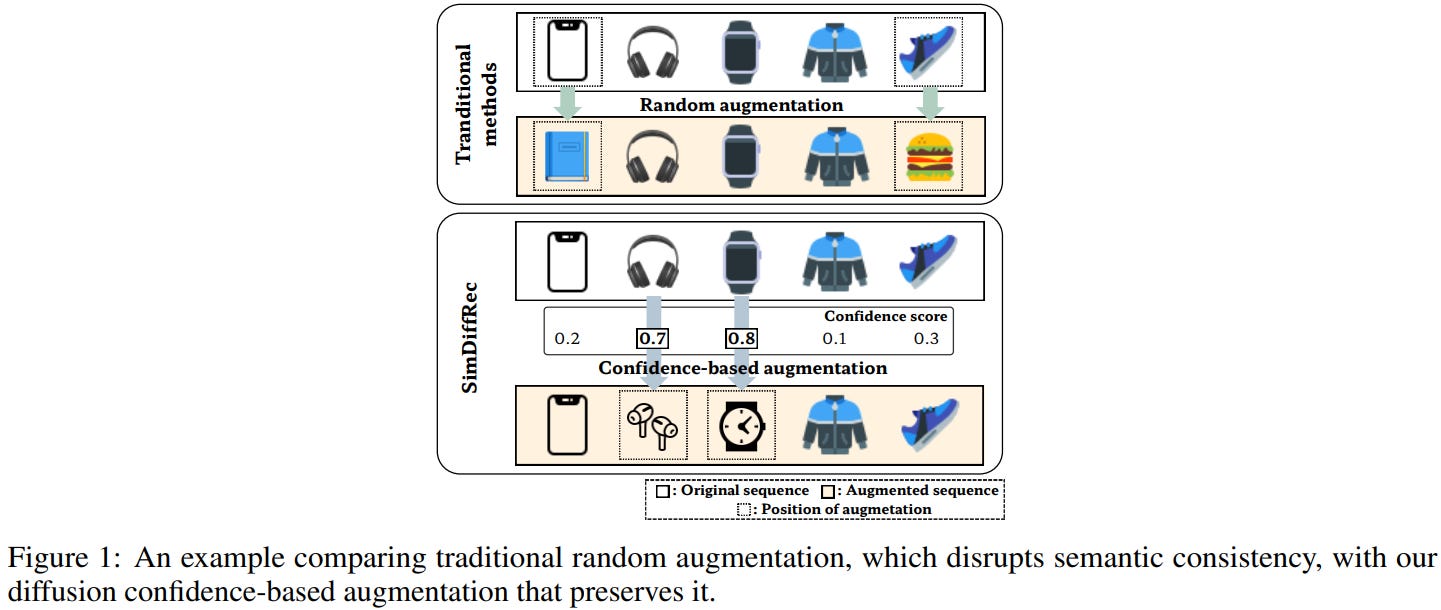
[9] Similarity-Guided Diffusion for Contrastive Sequential Recommendation
This paper from Sejong University introduces SimDiffRec for sequential recommendation that addresses the limitations of existing data augmentation methods which rely on random noise and position selection. The authors propose three key innovations: (1) semantic similarity-based noise generation that uses item embedding similarities instead of random Gaussian noise to preserve contextual information during diffusion, (2) confidence-based position selection that identifies augmentation positions based on the diffusion model's denoising confidence scores rather than random selection, and (3) hard negative sampling integrated with contrastive learning to capture subtle differences between positive and negative samples. The method leverages a diffusion model's forward and reverse processes while maintaining semantic consistency throughout the augmentation process.
📚 https://arxiv.org/abs/2507.11866
[10] UniConv: Unifying Retrieval and Response Generation for Large Language Models in Conversations
This paper from Mo et al. introduces UniConv, a unified LLM designed to handle both dense retrieval and response generation in conversational search systems, instead of using separate models for these tasks. The authors propose joint fine-tuning with three learning objectives: conversational dense retrieval, response generation, and a novel context identification instruction mechanism that helps the model identify relevant passages during training. To address data discrepancy issues, they incorporate well-formatted conversational search data that includes both relevant passages and corresponding ground-truth responses as supervision signals. Experimental evaluation on five conversational search datasets (TopiOCQA, QReCC, OR-QuAC, INSCIT, and FaithDial) demonstrates that UniConv outperforms existing baselines in both retrieval and generation tasks, achieving better consistency between retrieval effectiveness and response quality compared to systems using separate models.
📚 https://arxiv.org/abs/2507.07030

I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.