
Rethinking Negative Sampling for Knowledge Distillation in Retrieval, A Distillation Recipe for Small Language Model Search Agents, and More!
Vol.151 for Apr 06 - Apr 12, 2026

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Rethinking Negative Sampling for Knowledge Distillation in Retrieval, from Korea University
Distilling Reliable Search Agents into Small Language Models, from Liu et al.
Multi-View Sparse Filtering for Scalable Recommendation, from Alibaba
Uncovering the Impacts of Sub-Sequence Splitting on Sequential Recommendation, from Dang et al.
A Native Hierarchical Graph Index for Multi-Vector Similarity Search, from Beihang University
Adapting and Composing Causal LLMs into Omnimodal Bidirectional Encoders, from Boizard et al.
A Meta-Analysis of LLM-Based Retrieval on Established IR Benchmarks, from Staudinger et al.
Stress-Testing Generative Retrieval with Adversarial Identifiers, from Vienna University of Economics and Business
Feedback Adaptation for Retrieval-Augmented Generation, from Bang et al.
Automated Prompt Optimization for Multi-Agent Deep Research, from Zeta Alpha
[1] Beyond Hard Negatives: The Importance of Score Distribution in Knowledge Distillation for Dense Retrieval
This paper from Korea University challenges the prevailing focus on hard negative mining in knowledge distillation for dense retrieval. It argues that what really matters is how well the training data reflects the teacher’s full score distribution rather than just its hardest examples. The authors propose Stratified Sampling, a deterministic, parameter-free strategy that places K evenly spaced quantile anchors across the min-max normalized teacher scores of a candidate pool and picks the document closest to each anchor, so the selected negatives structurally mirror the shape of the teacher’s preferences. To isolate the effect of sampling from confounding factors, they build a fixed pool of 200 negatives per MS MARCO query, score them with Qwen3-Reranker-8B, and compare six sampling strategies (retriever-top, reranker-top, mid, low, random, stratified) under three student backbones (BERT-base, DistilBERT, co-condenser-marco) and two distillation objectives (KL-divergence and MarginMSE). Stratified Sampling consistently comes out on top, with random sampling a solid runner-up, while strategies skewed toward one end of the distribution (especially reranker-top) perform poorly and can even cause MarginMSE training to collapse.
📚 https://arxiv.org/abs/2604.04734

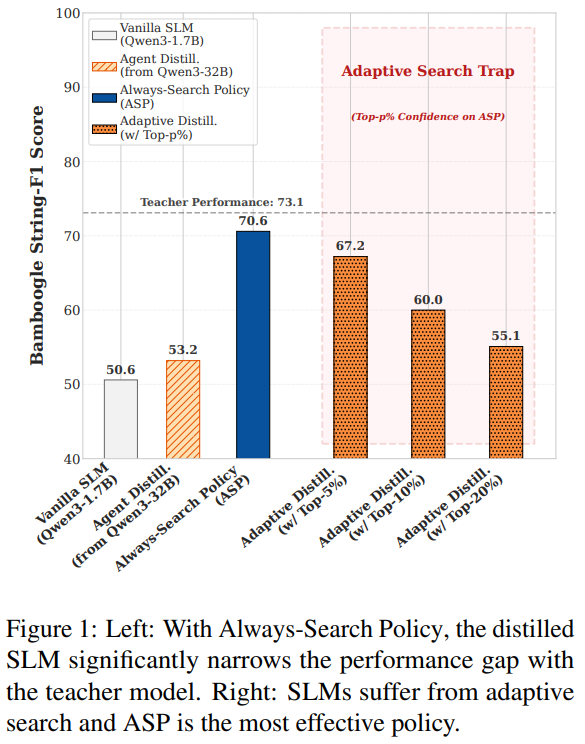
[2] Search, Do not Guess: Teaching Small Language Models to Be Effective Search Agents
This paper from Liu et al. tackles a counterintuitive failure mode in small language model (SLM) search agents: despite having less parametric knowledge than their larger counterparts, SLMs (under 4B parameters) actually invoke search tools less often and hallucinate more. Naively distilling agent trajectories from a 32B teacher into a 1.7B student barely helps because teacher trajectories quietly lean on parametric knowledge the student does not possess. The authors propose Always-Search Policy (ASP), a lightweight distillation paradigm that forces the student to retrieve and ground every essential piece of information through external search rather than guessing from memory. They filter teacher trajectories from Qwen3-32B on 18K HotpotQA questions, keeping only those with String-F1 ≥0.65 and consistent tool use, and stripping anything with "I remember" style answers. Experiments show that ASP-trained Qwen3-1.7B and Llama-3.2 students roughly match Qwen3-8B and close most of the gap to the 32B teacher, with gains of 17.3 points on Bamboogle and 15.3 on HotpotQA over standard distillation, search frequency rising from 1.72 to 2.84 calls per question, strong out-of-distribution generalization, and notably greater robustness to noisy retrieval. The authors then ask whether SLMs could search adaptively instead, using a confidence probe. The answer is no. A 32B model can safely self-answer its top 10% most confident queries, but SLMs degrade sharply even at the top 5%. For small agents, always searching beats trying to be selective.
📚 https://arxiv.org/abs/2604.04651
👨🏽💻 https://github.com/yizhou0409/Agentic-Rag
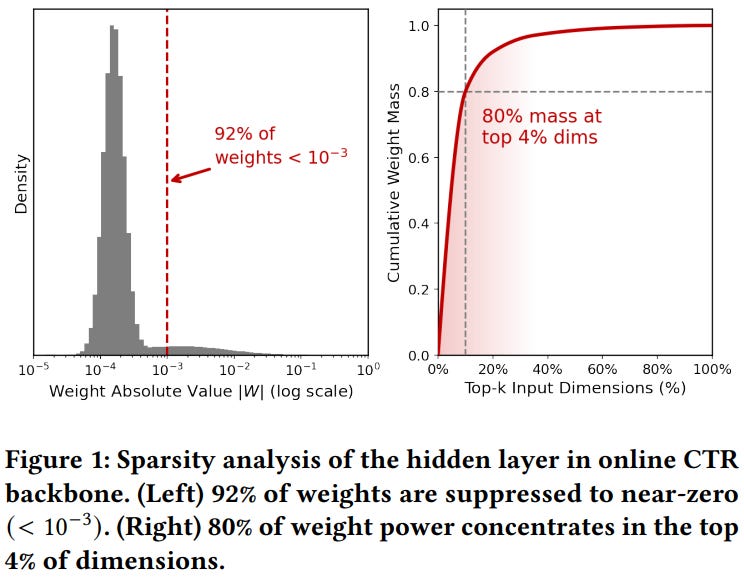
[3] Beyond Dense Connectivity: Explicit Sparsity for Scalable Recommendation
This paper from Alibaba introduces SSR (Explicit Sparsity for Scalable Recommendation), a framework that addresses why dense MLP backbones in CTR models hit performance ceilings when scaled up on sparse recommendation data. The authors first show empirically, by analyzing an industrial CTR model, that over 92% of learned weights in fully connected layers collapse to near-zero values and 80% of the weight mass concentrates in just the top 4% of input dimensions. This shows that dense architectures implicitly try (but fail efficiently) to behave sparsely, wasting capacity on suppressing noise rather than learning patterns. Building on this, SSR replaces global dense connectivity with a “filter-then-fuse” design: the input is decomposed into multiple parallel views, each subjected to dimension-level sparse filtering before a block-diagonal dense fusion stage, which cuts parameter complexity by a factor of 1/b relative to a standard FC layer. Across three public benchmarks (Avazu, Criteo, Alibaba) and a billion-scale AliExpress industrial dataset, SSR-D beats strong baselines including RankMixer, Wukong, AutoInt, and AutoFIS on AUC/GAUC/LogLoss, while SSR-S matches or exceeds RankMixer using roughly half its parameters and FLOPs. Scaling experiments show SSR continues to improve up to ~900M parameters, where dense MLPs saturate.
📚 https://arxiv.org/abs/2604.08011
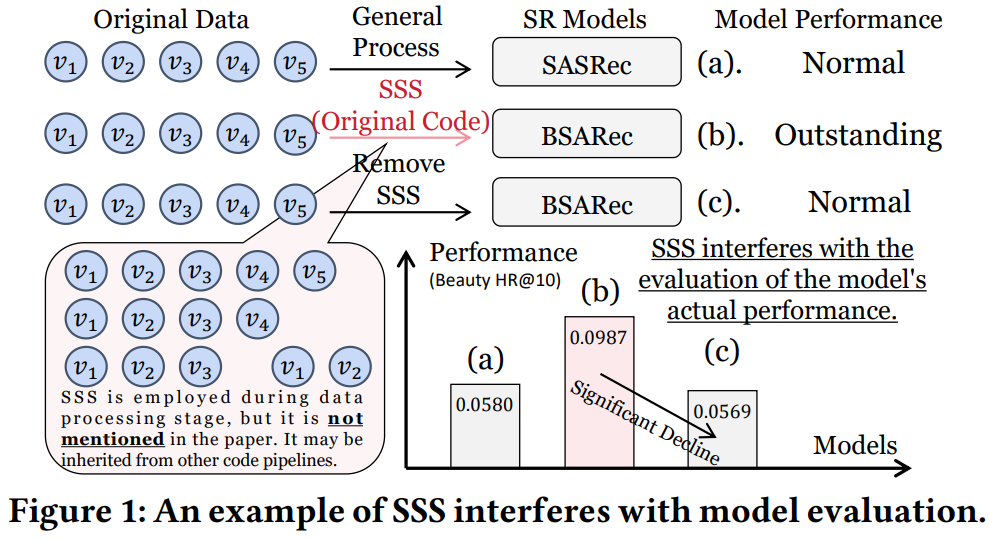
[4] Pay Attention to Sequence Split: Uncovering the Impacts of Sub-Sequence Splitting on Sequential Recommendation Models
This paper from Dang et al. is a reproducibility study showing that sub-sequence splitting (SSS) has been silently distorting the evaluation of recent sequential recommendation (SR) models. Sub-sequence Splitting is a data augmentation technique that turns one user interaction sequence into many contiguous sub-sequences via prefix splitting, suffix splitting, or sliding windows. After systematically scanning SR papers published between 2022 and 2026 in eight top venues plus TOIS and TKDE, the authors identified 17 qualifying papers and found that ten of them silently apply SSS during the data-reading stage without mentioning it in the text. When SSS is removed from the official implementations of these ten models (FMLPRec, DLFSRec, DiffuRec, BSARec, MUFFIN, CSRec, WaveRec, TV-Rec, FreqRec, WEARec) and tested on Beauty, Sports, Douyin, and LastFM, eight of them lose more than 40% in HR/NDCG and most fall below the 2018 SASRec baseline, overturning their claimed improvements. The authors then explain why SSS works by visualizing target and input-target distributions: it flattens the heavy-tailed target frequency, exposes low-frequency items as prediction targets, and dramatically increases the number of input contexts mapped to each target. The discussion calls for consistent splitting settings across baselines, explicit disclosure of SSS choices in papers, and notes that since multi-modal and cross-domain SR methods often inherit these backbones, the contamination likely extends well beyond classic SR.
📚 https://arxiv.org/abs/2604.05309
👨🏽💻 https://github.com/KingGugu/SSS4SR
[5] Unified and Efficient Approach for Multi-Vector Similarity Search
This paper from Beihang University introduces MV-HNSW, the first hierarchical graph index built natively for multi-vector data. It addresses a long-standing gap in multi-vector similarity search (MVSS) where prior methods like ColBERT, ColBERTv2, XTR, and WARP rely on a filter-and-refine paradigm over single-vector indexes and consequently get stuck in a recall-versus-latency dilemma. The authors first formalize a Unified Multi-Vector Similarity Search problem whose USim function generalizes MaxSim, Weighted Chamfer, and Aggregate γNN as special cases, and then prove that USim itself cannot serve as a graph edge weight because it violates three properties they identify as essential: symmetry, cardinality robustness, and query consistency. To fix this, they design an edge-weight function that averages bidirectional normalized similarity between two multi-vectors and combine it. Across seven real-world datasets derived from LoTTE and MS MARCO (ranging from 263M to nearly 9B token vectors), MV-HNSW sustains over 90% recall while delivering 5.6–14.0× lower search latency than the strongest baselines, and scales sub-linearly with query size and dimensionality.
📚 https://arxiv.org/abs/2604.02815
👨🏽💻 https://github.com/oldherd/MV-HNSW
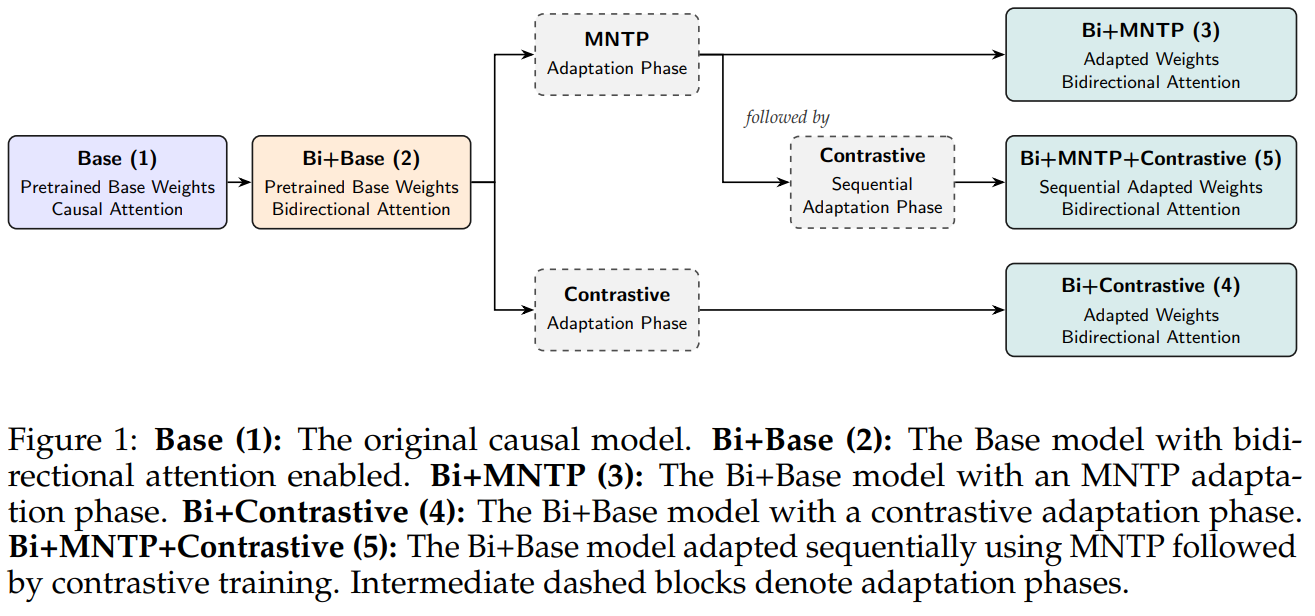
[6] BidirLM: From Text to Omnimodal Bidirectional Encoders by Adapting and Composing Causal LLMs
This paper from Boizard et al. presents BidirLM, a fully open-source framework for converting causal decoder LLMs (specifically Gemma3 and Qwen3) into bidirectional encoders that span text, vision, and audio. The authors first show that an often-omitted Masked Next-Token Prediction (MNTP) phase is what actually unlocks bidirectional attention for full-parameter fine-tuning tasks like XNLI and Seahorse, whereas contrastive (InfoNCE) training is mostly responsible for generic embedding quality on MTEB-style benchmarks. So a sequential Bi+MNTP+Contrastive pipeline matches or beats either objective alone across both regimes. To scale this adaptation without access to the original pre-training corpora, they tackle the resulting catastrophic forgetting with a dual strategy: linear weight merging of the MNTP-adapted checkpoint with the base model at roughly a 50% ratio, plus a lightweight multi-domain mixture (multilingual, math, code) that plateaus at just 20–30% of the data. Scaled up, this produces the BidirLM series (five models ranging from 270M to 2.5B parameters), and sets new open-source Pareto frontiers on MTEB, XTREME, MIEB, and MAEB benchmarks, with the omnimodal BidirLM-Omni-2.5B outperforming Nemotron-Omni-3B across all modalities at nearly half the parameter count.
📚 https://arxiv.org/abs/2604.02045
🤗 https://huggingface.co/BidirLM
[7] The LLM Effect on IR Benchmarks: A Meta-Analysis of Effectiveness, Baselines, and Contamination
This meta-analysis from Staudinger et al. examines 143 publications on two established IR benchmarks (TREC Robust04 and TREC Deep Learning 2020 (DL20)) to assess whether LLM-based retrieval systems represent genuine methodological progress or are inflated by weak baselines and data contamination. The authors identify what they call the “LLM effect”: recent LLM-incorporating systems achieve ~20% higher nDCG@10 on Robust04 since 2023 and 8.8% higher on DL20 versus the best TREC 2020 result, with the top performer (CoDIME) hitting 0.885 nDCG@10 on DL20. However, adapting the Data Contamination Quiz (DCQ) to the reranking setting reveals substantial benchmark contamination (26–41% on DL20 and 12–21% on Robust04) and filtering out contaminated topics does reduce effectiveness, though wide confidence intervals prevent any definitive conclusions. A further complication is metric heterogeneity: Robust04 alone sees 19 different metrics across 72 papers. The broader shift from MAP to nDCG@10 rewards top-rank precision and coincides temporally with LLM adoption and the 2021 BEIR release, which may itself be inflating apparent progress. The authors conclude that while the LLM effect is real and descriptively consistent, the IR community cannot yet cleanly separate genuine retrieval improvements from memorization artifacts and shifting evaluation priorities.
📚 https://arxiv.org/abs/2604.05766
👨🏽💻 https://github.com/MoritzStaudinger/LLM-effect
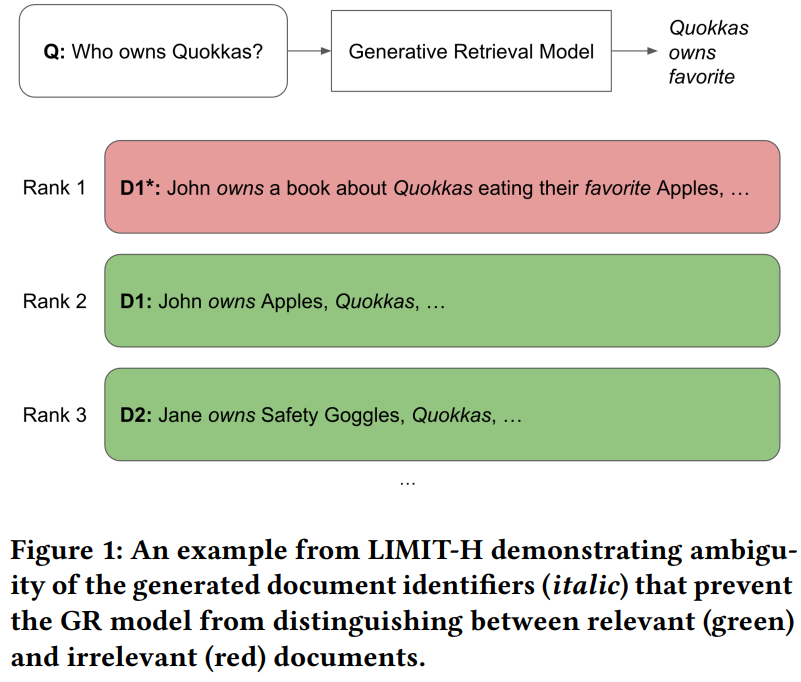
[8] Generative Retrieval Overcomes Limitations of Dense Retrieval but Struggles with Identifier Ambiguity
This paper from Vienna University of Economics and Business evaluates zero-shot generative retrieval (GR) models (specifically SEAL and MINDER) on the LIMIT benchmark. LIMIT is a synthetic dataset designed to expose the “vector bottleneck” that causes dense retrieval (DR) models to collapse under combinatorially complex queries. They confirm that GR largely sidesteps this geometric limitation, with MINDER reaching 0.988 R@2 versus near-zero for DR models, and even outperforming BM25 (0.857 R@2). However, the paper’s main contribution is introducing LIMIT-H and LIMIT-HS, adversarial extensions that inject hard negatives, i.e., documents sharing identical lexical content with relevant ones but carrying different semantics, to expose a distinct failure mode they term “identifier ambiguity”. When multiple documents share the same ngrams or pseudo-queries as docids, GR models can no longer generate identifiers unique to relevant documents, causing recall to collapse (default SEAL/MINDER drop to near-zero on LIMIT-H). A modified classical beam search partially mitigates this by filtering noisy low-probability ngrams, but performance still degrades substantially (MINDER drops from 0.954 to 0.450 R@2 on LIMIT-HS), and even oracle pseudo-queries fail to restore discriminative capacity because unique relevant identifiers get pruned during decoding. The authors conclude that GR has cleared the vector bottleneck but hit a “second wall” that current identifier design and decoding strategies are insufficient to handle.
📚 https://arxiv.org/abs/2604.05764
👨🏽💻 https://anonymous.4open.science/r/GR-on-LIMIT/
[9] Feedback Adaptation for Retrieval-Augmented Generation
This paper from Bang et al. tackles a blind spot in how Retrieval-Augmented Generation systems are evaluated. Standard benchmarks measure aggregate accuracy on static test sets, but deployed RAG systems are constantly being corrected by users and experts, and existing protocols say nothing about how well a system actually absorbs those corrections. The authors formalize this as *feedback adaptation* and propose two evaluation axes to measure it:
Correction lag: the delay between when feedback is given and when the system’s outputs reliably reflect it.
Post-feedback performance: accuracy on semantically related queries (not just lexical repeats) once the correction is in place.
Using these metrics, they show that training-based approaches like RAFT face a structural trade-off: shrinking correction lag by cutting fine-tuning steps sharply degrades post-feedback accuracy. As a proof of concept, they introduce PatchRAG, a deliberately minimal inference-time method that stores feedback as (query, answer, evidence) tuples and retrieves them using a dual scoring function combining intent similarity (query-to-query) and context grounding (query-to-evidence), then injects the retrieved patches into the prompt via in-context learning. On Natural Questions, TriviaQA, and HotpotQA with Llama-3 8B and bge-m3, PatchRAG achieves both the lowest correction lag and the highest post-feedback performance. Additional analyses show that standard query-to-context retrieval barely benefits from feedback at all (making intent-aware retrieval essential), that the method degrades gracefully under noisy, blank, vague, or conflicting feedback, and that the gains hold across BM25, DPR, and bge-m3 retrievers.
📚 https://arxiv.org/abs/2604.06647
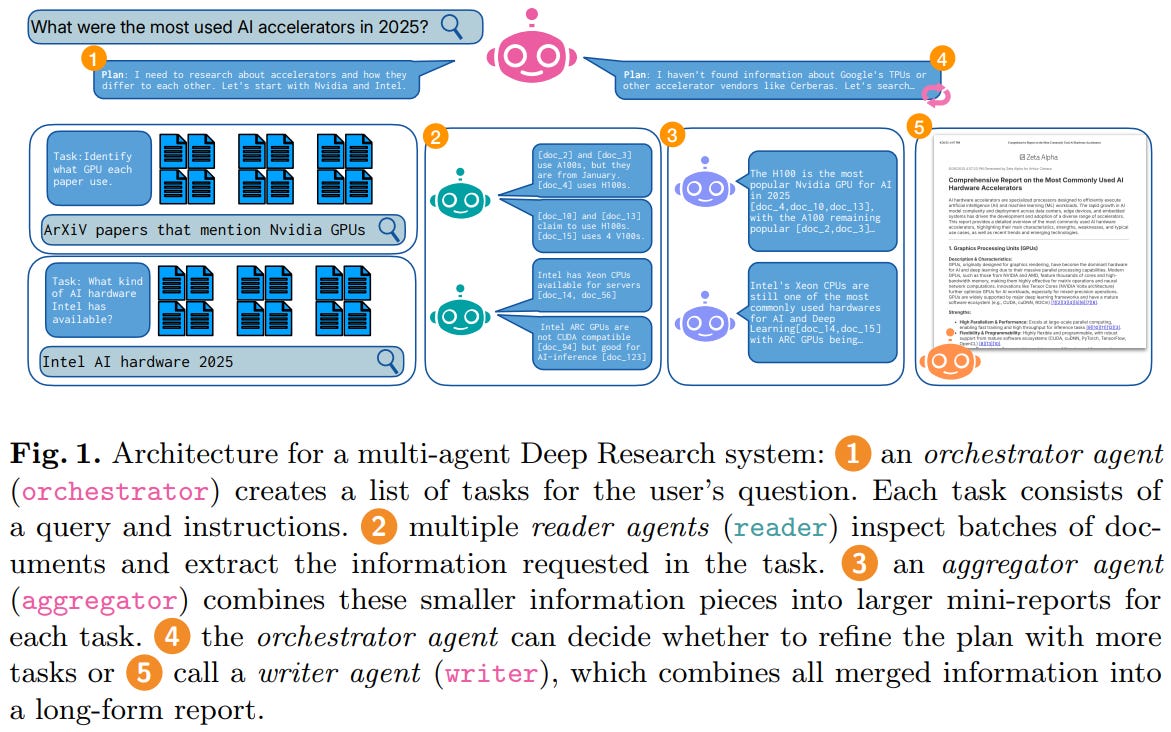
[10] Self-Optimizing Multi-Agent Systems for Deep Research
This paper from Zeta Alpha tackles the brittleness of Deep Research (DR) systems, which usually depend on hand-crafted prompts that break whenever the model, domain, or task shifts. The authors describe a multi-agent DR architecture built around four roles: an orchestrator that plans and issues sub-tasks, parallel reader agents that extract evidence from batches of retrieved documents, an aggregator that consolidates findings into mini-reports, and a writer that produces the final cited long-form answer. Rather than tuning each agent’s prompt by hand, they treat the prompts as trainable parameters and compare four optimizers (TextGrad, GEPA with its default meta-prompt, GEPA with a task-specific meta-prompt, and OpenAI’s built-in prompt optimizer) on the Computer Science subset of ScholarQA, with GPT-4.1-mini powering the agents, optimizers, and LLM judge. Across the board, optimization clearly helped when starting from a minimal one-line prompt, with GEPA using a custom meta-prompt scoring highest at 0.705 versus the 0.513 baseline and even beating the year-long expert-crafted prompt (0.667). Gains shrank once a strong expert prompt was already in place, suggesting diminishing returns, and OpenAI’s general-purpose optimizer lagged behind because it lacks access to rubric feedback and execution traces. The authors conclude that automated prompt optimization is a viable alternative to manual prompt engineering for industrial DR systems.
📚 https://arxiv.org/abs/2604.02988
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.