


Identifying Cost-Effective CPU Architectures for Vector Databases, Lessons from Pinterest's Ad Conversion Models, and More!
Vol.104 for May 12 - May 18, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
A Comprehensive CPU Performance Analysis for Vector Similarity Search, from Kuffo et al.
Designing Advanced Learning-to-Rank Models for E-commerce Search, from Airbnb
Comparing OCR and Vision-Based Document Retrieval, from Most et al.
A Traffic Allocation Strategy for Cold-Start Items in Recommendation Systems, from Google
Techniques for Optimizing Embedding Tables in Large-Scale Ad Recommendation, from Pinterest
Efficient Knowledge Distillation from LLMs for E-commerce Search, from Walmart
Measuring and Mitigating the Distracting Effect in RAG Systems, from Amiraz et al.
A Coarse-to-Fine Multimodal Retrieval Framework for Knowledge-Based Visual Question Answering, from Microsoft
A Comprehensive Survey on LLMs in Multimodal Recommender Systems, from López-Ávila et al.
Modeling User Interest Life Cycles for Enhanced Recommendation Performance, from NetEase
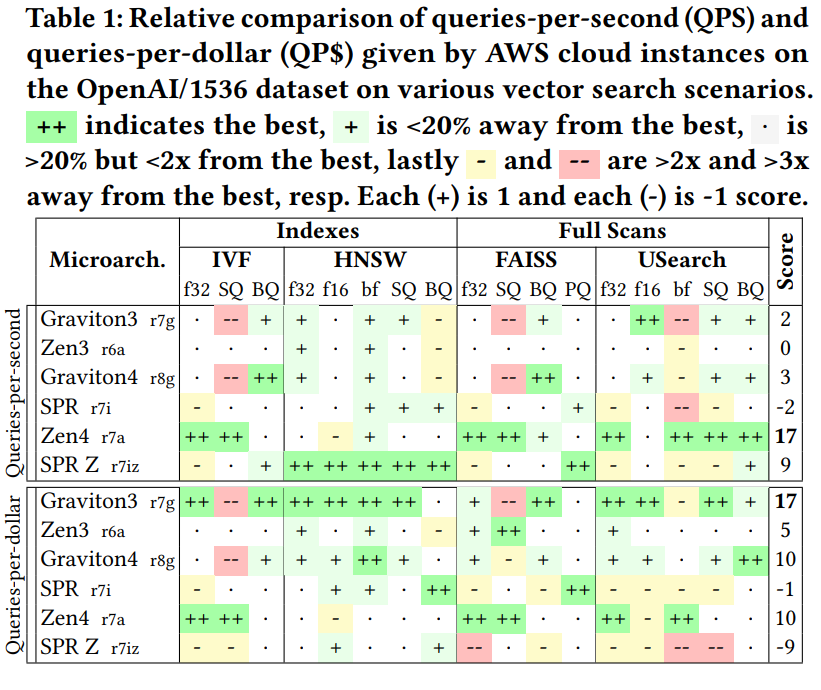
[1] Bang for the Buck: Vector Search on Cloud CPUs
This paper from Kuffo et al. evaluates the performance and cost-efficiency of vector search operations across different CPU microarchitectures available in AWS cloud services. The authors benchmark five AWS CPU types (AMD Zen3/Zen4, Intel Sapphire Rapids/Sapphire Rapids Z, and AWS Graviton3/4) running vector search workloads with various indexing methods (IVF, HNSW, full scans) and quantization techniques (float32, float16, binary quantization, etc.). Their findings reveal that optimal CPU choice depends significantly on the specific search algorithm and vector quantization level used. For instance, AMD's Zen4 delivers nearly 3x more queries per second than Intel Sapphire Rapids on IVF indexes with float32 vectors, but Intel performs better on HNSW indexes. Most surprisingly, when measuring queries per dollar (QP$), AWS Graviton3 provides the best overall value despite being an older architecture, even outperforming its successor Graviton4 in many scenarios. The authors attribute these performance differences not just to SIMD (Single Instruction Multiple Data) capabilities, but also to how each search algorithm's data access patterns interact with CPU cache performance and memory access characteristics.
📚 https://arxiv.org/abs/2505.07621
[2] Beyond Pairwise Learning-To-Rank At Airbnb
This paper from Airbnb introduces a learning-to-rank (LTR) approach for Airbnb's search system that go beyond traditional pairwise LTR models. The authors present the "SAT theorem," which states that ranking algorithms can only simultaneously achieve two of three desired properties: scalability, accuracy, and total order. They address limitations of traditional pairwise LTR, which cannot capture interactions between items being compared, by developing two new frameworks: "true-pairwise LTR," which allows direct interaction between two items being compared, and "all-pairwise LTR," which considers how each listing interacts with all other listings through superiority and similarity features. To maintain scalability, they implement these computationally intensive models as second-stage rankers operating on a smaller subset of listings pre-filtered by traditional pairwise LTR. Offline and online experiments demonstrate that all-pairwise LTR with superiority-similarity features significantly improves booking rates and other key metrics, leading to its full deployment for all Airbnb users in early 2025.
📚 https://arxiv.org/abs/2505.09795
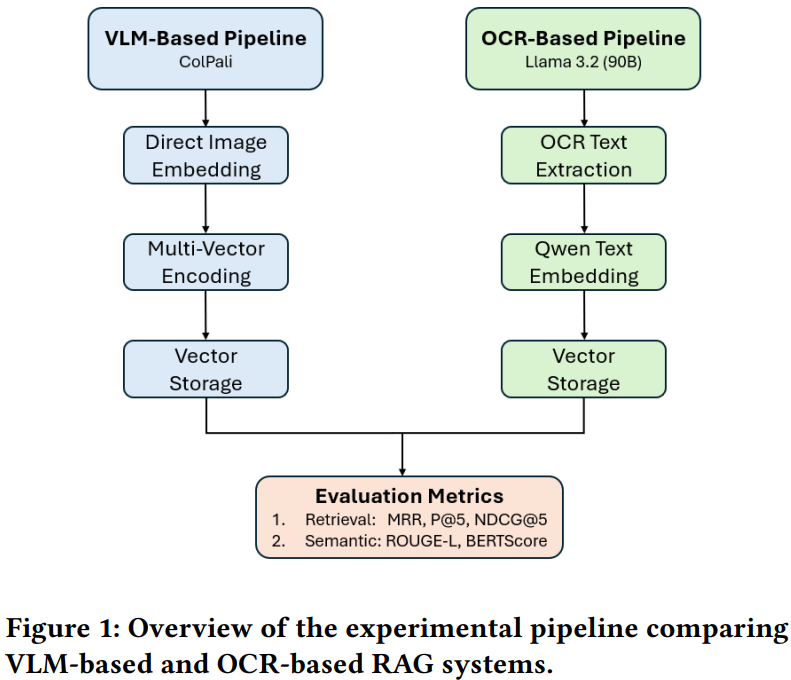
[3] Lost in OCR Translation? Vision-Based Approaches to Robust Document Retrieval
This paper from Most et al. presents a systematic comparison between vision-based and OCR-based approaches to RAG systems for document processing. The authors compare ColPali, a vision-language model (VLM) that directly embeds document images, against traditional OCR-based pipelines using Llama 3.2 (90B) and Nougat OCR across documents with varying levels of degradation. They introduce DocDeg, a dataset of 4,196 diverse documents categorized into four quality levels, and develop a semantic answer evaluation benchmark to assess end-to-end question-answering performance. Their findings reveal that while VLM-based approaches offer computational efficiency advantages (faster embedding time, lower memory usage), OCR-based pipelines consistently achieve superior retrieval accuracy and semantic answer quality across all degradation levels. Interestingly, they observe that VLM-based approaches struggle to generalize to unseen document types they haven't been fine-tuned on, while OCR-based systems demonstrate better robustness.
📚 https://arxiv.org/abs/2505.05666
[4] Item Level Exploration Traffic Allocation in Large-scale Recommendation Systems
This paper from Google addresses the item cold-start problem in large-scale recommendation systems by developing an intelligent exploration traffic allocation strategy for newly ingested content. The authors propose a probabilistic model that predicts an item's likelihood of becoming "discoverable" (capable of being recommended by the exploitation engine) based on various item features and engagement signals collected during exploration. Their approach segments items into three categories based on predicted discoverability: high (requiring reduced traffic), moderate (needing maximum exploration), and low (allocated traffic proportional to user feedback). The system continuously adapts to changes in item volume and traffic availability while maintaining efficiency through regular model retraining.
📚 https://arxiv.org/abs/2505.09033

[5] The Evolution of Embedding Table Optimization and Multi-Epoch Training in Pinterest Ads Conversion
This paper from Pinterest presents key advancements in optimizing embedding tables and multi-epoch training for their ads conversion prediction models. The authors introduce two main contributions: 1) A "Sparse Optimizer" that applies higher learning rates specifically to embedding table parameters, addressing slow convergence caused by gradient sparsity and improving model performance; and 2) a "Frequency-Adaptive Learning Rate" (FAL) technique that selectively reduces learning rates for infrequent embedding table rows to mitigate multi-epoch overfitting while preserving performance for frequently accessed rows. They demonstrate how multi-task learning models experience varying degrees of overfitting across objectives depending on label sparsity, with sparser objectives (like checkout prediction) showing more severe overfitting.
📚 https://arxiv.org/abs/2505.05605
[6] Knowledge Distillation for Enhancing Walmart E-commerce Search Relevance Using Large Language Models
This paper from Walmart presents a knowledge distillation framework for improving e-commerce search relevance at Walmart by transferring knowledge from LLMs to smaller, more efficient models. The authors first train a teacher model using a 7B-parameter LLM (Mistral-7B) with soft targets converted from human editorial labels, then distill this knowledge into a BERT-Base student model using Margin-MSE loss, which focuses on preserving the relevance margins between pairs of products for a given query. Instead of using only labeled training data, they significantly expand the student model's dataset by generating unlabeled query-item pairs from search logs and labeling them with the teacher model's predictions. Their experiments show that the student model's performance improves as the augmented dataset grows, with Margin-MSE loss outperforming pointwise cross-entropy loss. Remarkably, the student model achieves comparable or even superior performance to the teacher model despite being 60 times smaller and lacking access to item descriptions that benefited the LLM.
📚 https://arxiv.org/abs/2505.07105
[7] The Distracting Effect: Understanding Irrelevant Passages in RAG
This paper from Amiraz et al. addresses the challenges introduced by irrelevant passages in RAG systems that distract LLMs and lead to incorrect responses. The authors propose a quantifiable measure of a passage's "distracting effect" relative to a query and demonstrate its robustness across different LLMs. They identify that passages from stronger retrievers tend to be more distracting than those from weaker ones, and develop multiple methods to generate hard distracting passages, including retrieval-based approaches and synthetically generated passages in four categories (related topic, hypothetical, negation, and modal statements). Their experiments show that combining these different methods yields more distracting passages than any single method alone. When fine-tuning LLMs with these carefully selected distracting passages, they achieved up to a 7.5% increase in answering accuracy compared to models fine-tuned on conventional RAG datasets.
📚 https://arxiv.org/abs/2505.06914
[8] OMGM: Orchestrate Multiple Granularities and Modalities for Efficient Multimodal Retrieval
This paper from Microsoft introduces an approach to enhance Knowledge-Based Visual Question Answering (KB-VQA) through a sophisticated coarse-to-fine, multi-step retrieval system. The authors address the inherent challenges of multimodal retrieval by harmonizing diverse modalities (images and text) and knowledge granularities within both queries and knowledge bases. Their system employs a three-step process: first conducting coarse-grained cross-modal entity searching using entity summaries and query images, then performing hybrid-grained multimodal fusion reranking that leverages both coarse and fine-grained information to select the most relevant entity, and finally applying fine-grained text reranking to extract the most pertinent sections for generation. The system's effectiveness stems from its ability to align information granularities appropriately across retrieval steps and propagate similarity scores between stages, outperforming approaches that rely heavily on extensive fine-tuning.
📚 https://arxiv.org/abs/2505.07879
[9] A Survey on Large Language Models in Multimodal Recommender Systems
This paper from López-Ávila et al. presents a comprehensive survey of the integration of LLMs in Multimodal Recommender Systems (MRS). The authors propose a taxonomy that organizes LLM integration strategies into three main categories: LLM Methods (including prompting techniques, training strategies, and data type adaptation), MRS-Specific Techniques (covering disentanglement, alignment, and fusion), and emerging trends. The survey highlights how LLMs offer new opportunities for MRS through semantic reasoning, in-context learning, and dynamic input handling, addressing persistent challenges like data sparsity and cold-start problems. Unlike previous encoder-centric surveys, this work focuses on LLM-specific capabilities and includes transferable techniques from related recommendation domains.
📚 https://arxiv.org/abs/2505.09777

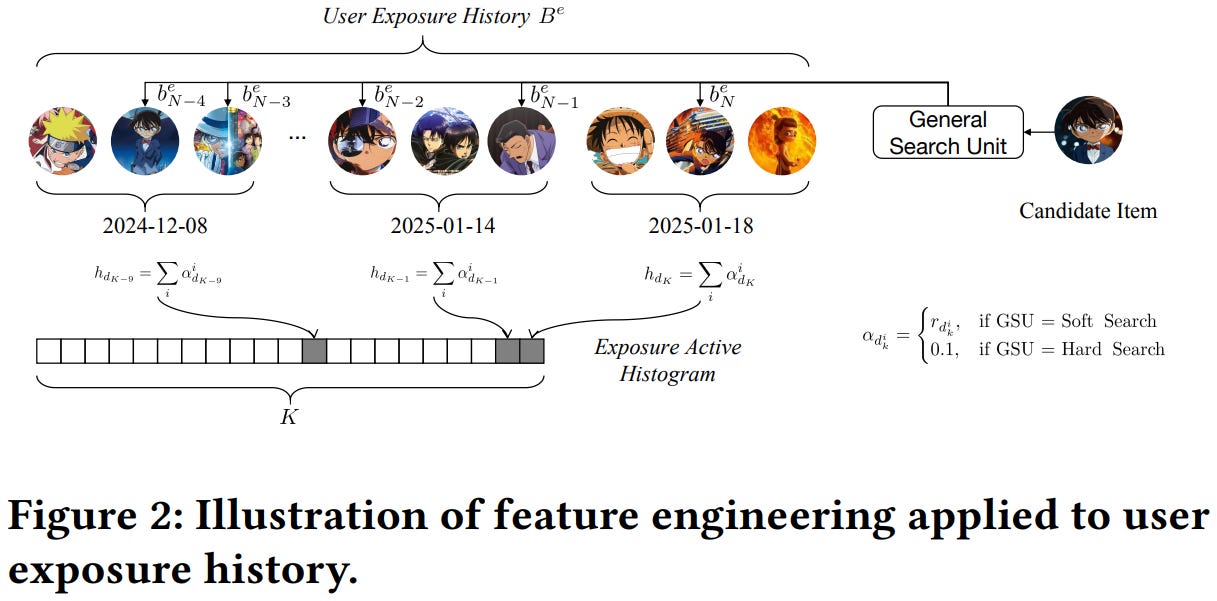
[10] Interest Changes: Considering User Interest Life Cycle in Recommendation System
This paper from NetEase introduces the Deep Interest Life-cycle Network (DILN), which addresses the challenge of modeling user interest evolution throughout its life cycle in recommendation systems. The authors identify that user interests typically follow a predictable pattern: an emergent phase (growing curiosity), a stable phase (consistent engagement), and a declining phase (diminishing attention). Current recommendation models fail to properly account for these phases, either over-recommending declining interests or under-promoting emergent ones. DILN consists of two key components: the Interest Life-cycle Encoder Module (ILEM), which constructs and encodes historical activity histograms into dense representations, and the Interest Life-cycle Fusion Module (ILFM), which injects these encoded features into a multi-expert network framework to dynamically adapt to different interest phases.
📚 https://arxiv.org/abs/2505.08471
Extras: Benchmarks
⏱️ WixQA: A Multi-Dataset Benchmark for Enterprise Retrieval-Augmented Generation
WixQA is a multi-dataset benchmark for evaluating enterprise RAG systems introduced by Wix AI Research. It addresses the need for domain-specific evaluation in customer support scenarios, featuring three complementary datasets derived from Wix.com support interactions and a comprehensive knowledge base snapshot. The benchmark includes WixQA-ExpertWritten (200 real user queries with expert-authored answers), WixQA-Simulated (200 expert-validated QA pairs distilled from user dialogues), and WixQA-Synthetic (6,221 LLM-generated QA pairs systematically derived from knowledge base articles).
📝 https://arxiv.org/abs/2505.08643
👨🏽💻 https://huggingface.co/datasets/Wix/WixQA
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.