
Empirical Patterns in Real-World Agentic Search Sessions, How Many Dimensions Do You Really Need for Top-k Retrieval?, and More!
Vol.141 for Jan 26 - Feb 01, 2026

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Empirical Patterns in Real-World Agentic Search Sessions, from Ning et al.
A Critical Analysis of Datasets for Sequential Recommendation, from Sber AI Lab
How Many Dimensions Do You Really Need for Top-k Retrieval?, from Wang et al.
Landmark Token Pooling for Scalable Document Embeddings, from IBM Research
Differentiable Semantic IDs for Generative Recommendation, from Fu et al.
Masked Diffusion Models for Generative Recommendation, from Alibaba
Asynchronous Sequence Scaling for Ads Ranking at Scale, from Meta
Sub-Question Decomposition for Coverage-Aware Document Reranking in Long-Form RAG, from Ju et al.
A Dynamic Clustering Paradigm for Large-Scale Item Indexing, from ByteDance
Purified Codebooks and Integrated Semantics for Generative Sequential Recommendation, from Fang et al.
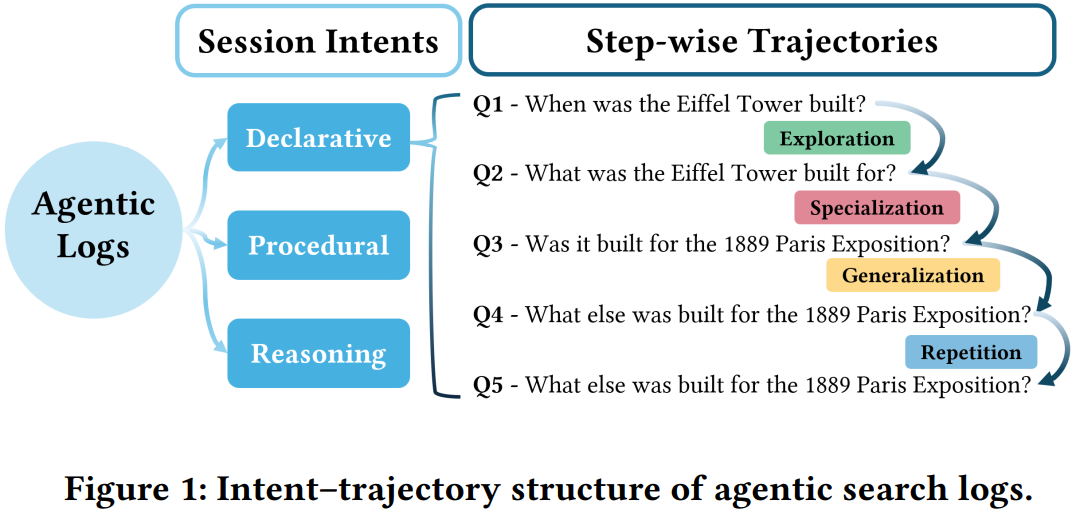
[1] Agentic Search in the Wild: Intents and Trajectory Dynamics from 14M+ Real Search Requests
This paper from Ning et al. presents a large-scale empirical analysis of LLM-powered agentic search behavior using 14.44 million search requests collected from DeepResearchGym, an open-source search API accessed by external agentic clients. The authors develop a measurement framework combining LLM-based annotation for session-level intent (Declarative, Procedural, Reasoning) and trajectory-level query reformulation (Specialization, Generalization, Exploration, Repetition), along with a novel metric called Context-driven Term Adoption Rate (CTAR) that quantifies whether newly introduced query terms can be traced to previously retrieved evidence. Key findings reveal that over 90% of multi-turn sessions contain at most ten steps with 89% of inter-step intervals under one minute. Behavior varies significantly by intent: Declarative (fact-seeking) sessions exhibit high repetition rates that increase over time, suggesting agents enter near-duplicate loops when retrieval proves unproductive, while Reasoning sessions sustain broader exploration throughout. The CTAR analysis shows that on average 54% of newly introduced query terms appear in accumulated evidence context, with measurable contributions from earlier steps beyond just the most recent retrieval, indicating genuine cross-step evidence integration rather than independent single-shot queries. The authors identify a “drill-down bias” where agents favor local refinement over deliberate broadening, and propose practical design implications including repetition-aware early stopping mechanisms.
📚 https://arxiv.org/abs/2601.17617
[2] An Analysis of Sequential Patterns in Datasets for Evaluation of Sequential Recommendations
This paper from Sber AI Lab addresses an evaluation problem in sequential recommender systems research: the need to verify that datasets actually contain meaningful sequential patterns before using them to benchmark sequential models. The authors propose three complementary approaches based on random shuffling of user interaction sequences: a model-agnostic sequential rules method that counts 2-grams and 3-grams before and after shuffling, and two model-based approaches using SASRec and GRU4Rec that measure performance deterioration and recommendation list stability when test sequences are shuffled. Applying these methods to 19 widely-used datasets from top-tier venues (RecSys, SIGIR, CIKM), they find that several popular benchmarks including Yelp, RetailRocket, Foursquare, Gowalla, Steam, and Diginetica exhibit weak sequential structure, with performance drops of less than 10% after shuffling, suggesting these datasets are unsuitable for evaluating sequential recommenders. The paper further investigates how preprocessing choices (N-core filtering) and postprocessing (seen item removal) affect detected sequential structure, showing that weaker filtering can mask sequential patterns while seen item filtering introduces confounding effects on datasets with repetitive consumption. They also categorize datasets into five behavioral groups: “bag-of-items” datasets with no sequential structure, datasets with repetitive patterns, datasets with simple sequential dependencies, “bag-of-recent-items” datasets where recency but not order matters, and datasets with complex sequential patterns suitable for benchmarking.
📚 https://dl.acm.org/doi/10.1145/3787969
👨🏽💻 https://github.com/Antondfger/Does-It-Look-Sequential/tree/TORS/
[3] R²ᵏ is Theoretically Large Enough for Embedding-based Top-k Retrieval
This paper from Wang et al. investigates the minimal embedding dimension (MED) required for perfect top-k retrieval in vector spaces, addressing whether geometric constraints fundamentally limit embedding-based retrieval systems. The authors derive tight theoretical bounds showing MED = Θ(k) for inner product, cosine similarity, and Euclidean distance scoring functions. Crucially, this bound depends only on k (the maximum answer set size) and is independent of m (the universe size), contradicting prior empirical work that suggested a polynomial relationship between dimension and universe size. The paper also analyzes a “centroid setting” (MED-C) where query embeddings are constrained to be centroids of their answer sets, proving an O(k² log m) upper bound via probabilistic methods. These findings fundamentally reframe the limitations of embedding-based retrieval: since even 2k dimensions theoretically suffice for any top-k retrieval task regardless of corpus size, performance bottlenecks in practice stem from learnability challenges, i.e., how to actually learn the required embeddings from data.
📚 https://arxiv.org/abs/2601.20844
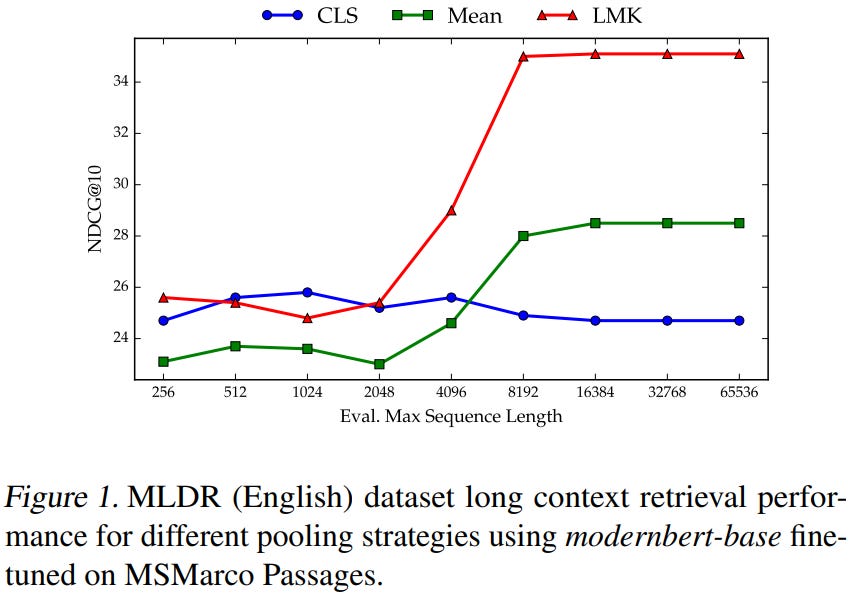
[4] LMK > CLS: Landmark Pooling for Dense Embeddings
This paper from IBM Research addresses limitations in how neural text encoders collapse variable-length token sequences into fixed-dimensional representations. The authors identify that [CLS] pooling suffers from positional bias due to RoPE’s long-term decay (attention weights attenuate for distant tokens, concentrating information toward sequence beginnings), while mean pooling dilutes salient local features by uniformly weighting all tokens regardless of semantic importance. The authors propose Landmark (LMK) pooling, which partitions sequences into chunks, inserts special landmark tokens (using the existing [SEP] token) at regular intervals, and mean-pools only the landmark embeddings to form the final representation. Experiments across ModernBERT, gte-en-mlm-base, and multilingual models (mmBERT, gte-multilingual-base) demonstrate that LMK pooling matches or exceeds CLS/mean pooling on short-context benchmarks (BEIR, MTEBv2, MIRACL) while delivering substantial gains on long-context tasks (MLDR, LongEmbed, COIR).
📚 https://arxiv.org/abs/2601.21525
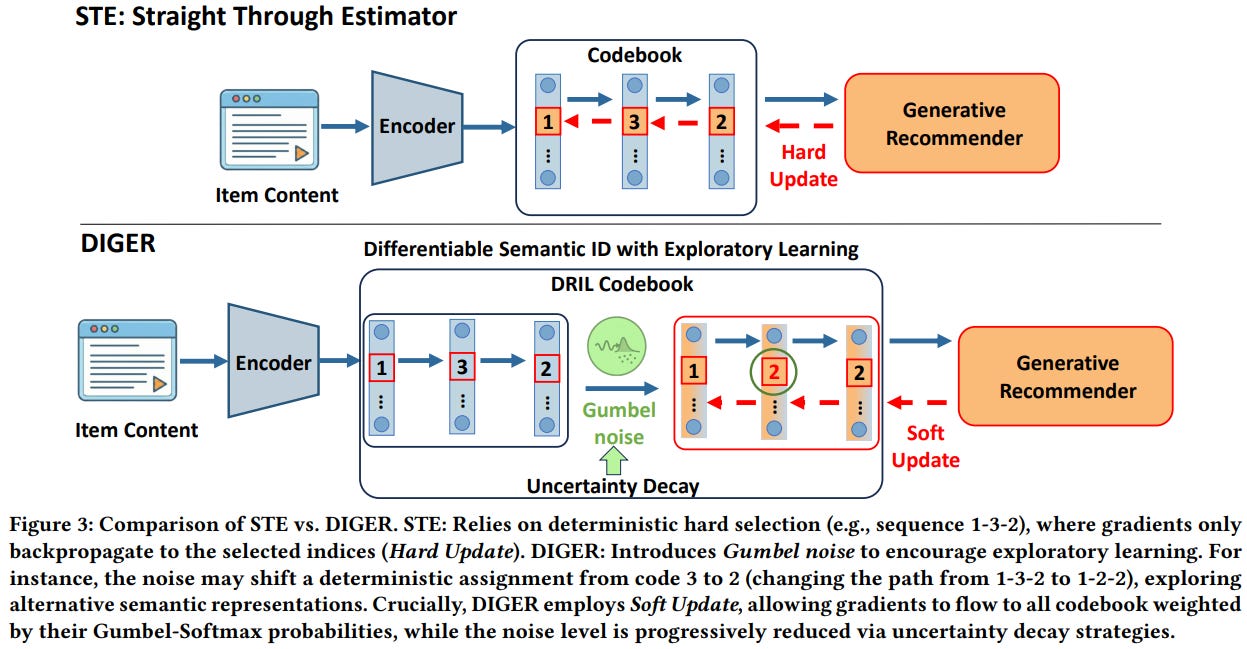
[5] Differentiable Semantic ID for Generative Recommendation
This paper from Fu et al. introduces DIGER (Differentiable Semantic ID for Generative Recommendation), a framework that addresses a limitation in generative recommender systems where semantic IDs (SIDs) are typically learned via RQ-VAE for content reconstruction and then frozen, creating an objective mismatch since the recommendation loss cannot backpropagate through the discrete indexing process. While making semantic indexing differentiable is the intuitive solution, naive approaches using straight-through estimators (STE) suffer from codebook collapse, where early deterministic assignments cause a small subset of codes to dominate. DIGER solves this through two key innovations: DRIL (Differentiable Semantic ID with Exploratory Learning), which injects Gumbel noise into assignment logits to encourage exploration over codebook entries while maintaining differentiability via soft updates during backpropagation; and two uncertainty decay strategies that progressively reduce the noise to transition from exploration to exploitation, aligning training behavior with deterministic inference. The framework uses hard SID assignments in the forward pass for indexing but computes gradients through Gumbel-Softmax probabilities, enabling end-to-end optimization of both the tokenizer and recommender.
📚 https://arxiv.org/abs/2601.19711
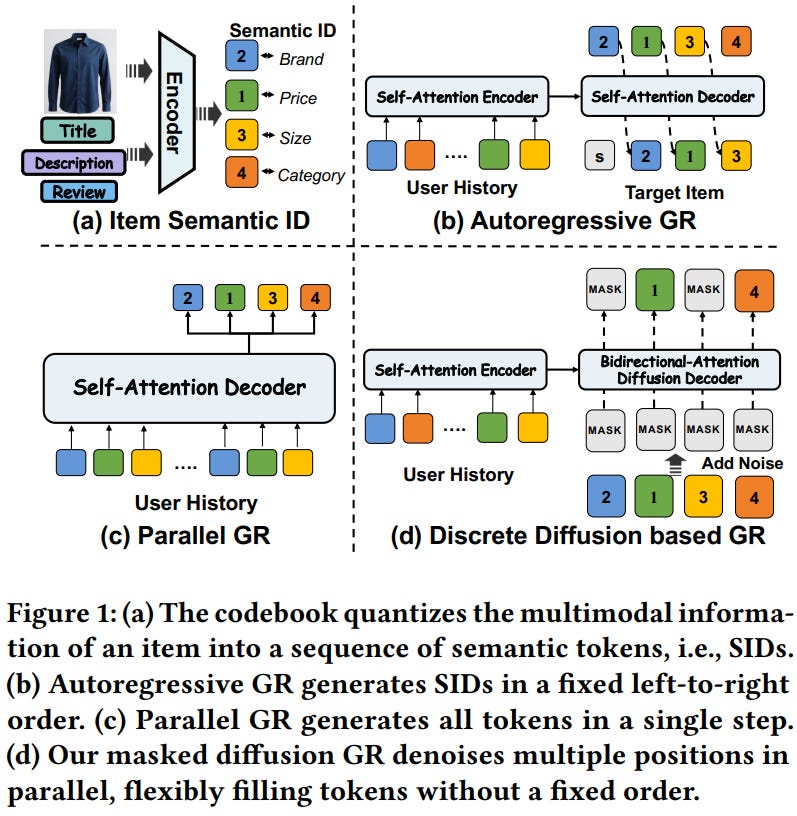
[6] Masked Diffusion Generative Recommendation
This paper from Alibaba introduces MDGR (Masked Diffusion Generative Recommendation), a framework that reframes generative recommendation as a discrete masked diffusion process rather than relying on the conventional autoregressive decoding paradigm. The authors identify three limitations of autoregressive approaches: inability to capture global dependencies across multi-dimensional semantic IDs, the implicit assumption that all users attend to item attributes in the same fixed order, and inefficient sequential inference.
MDGR addresses these through three core innovations:
Adopting OPQ-based parallel codebooks where each token resides in an independent semantic subspace, enabling bidirectional context modeling and arbitrary-order denoising.
A training regime that dynamically controls noise along both temporal and sample dimensions, using global curriculum scheduling that progressively increases masking difficulty as training proceeds, combined with history-aware mask allocation that focuses supervision on harder-to-predict semantics.
A warm-up–based two-stage parallel decoding strategy where initial steps decode single positions to establish semantic anchors, followed by confidence-guided parallel prediction of multiple positions per step, reducing inference complexity.
The framework treats SID generation as an absorbing Markov process where tokens transition independently to a [MASK] state, with the decoder learning to reconstruct masked positions given user history and a difficulty-aware embedding. Experiments on Amazon Electronics, Amazon Books, and a billion-scale industrial dataset demonstrate 7.17%–10.78% improvements over baselines, including TIGER, Cobra, and RPG, while online A/B testing yielded 1.20% revenue lift and 3.69% GMV increase.
📚 https://arxiv.org/abs/2601.19501
[7] LLaTTE: Scaling Laws for Multi-Stage Sequence Modeling in Large-Scale Ads Recommendation
This paper from Meta introduces LLaTTE (LLM-Style Latent Transformers for Temporal Events), a scalable transformer architecture for production ads recommendation that demonstrates recommendation systems follow predictable power-law scaling laws similar to LLMs. The authors systematically investigate scaling across model depth, width, sequence length, and data quality, finding that semantic content features (from LLaMA and multimodal encoders) don’t just additively improve performance but fundamentally “bend the scaling curve,” serving as a prerequisite for deeper architectures to effectively utilize their capacity. To overcome the tension between scaling benefits and strict production latency constraints, they introduce a two-stage architecture: an asynchronous upstream user model that processes long user histories (up to 5000 events) with 45x the sequence FLOPs of the online ranker, generating cached user embeddings that the latency-constrained downstream model consumes at request time. Key findings include that sequence length provides the steepest scaling slope, and upstream improvements transfer to downstream ranking with approximately 50% efficiency despite the information bottleneck.
📚 https://arxiv.org/abs/2601.20083
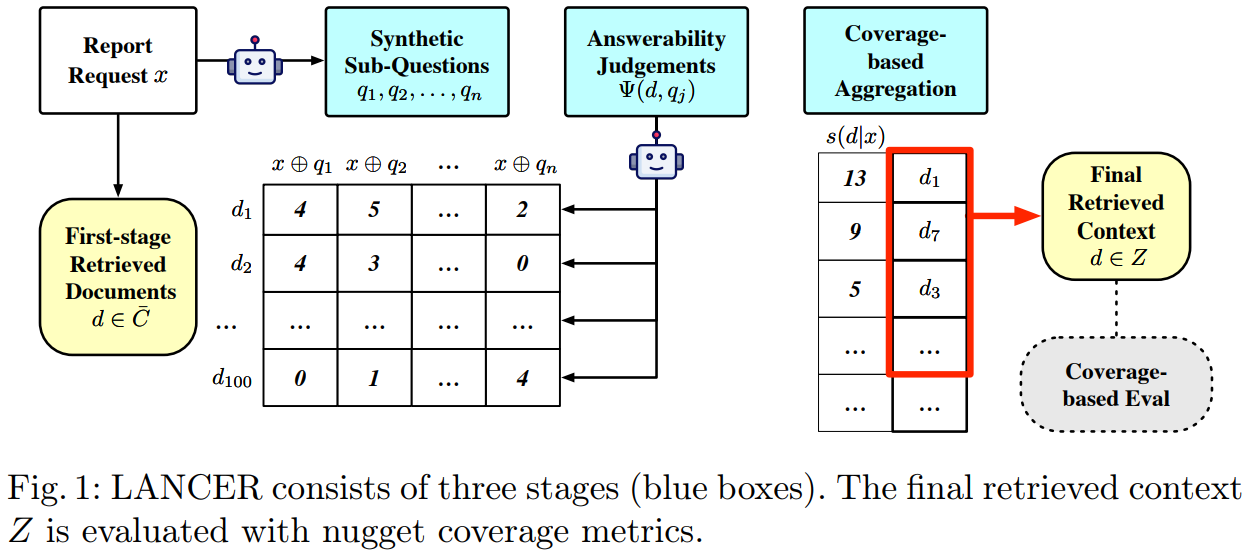
[8] LANCER: LLM Reranking for Nugget Coverage
This paper from Ju et al. introduces LANCER, an LLM-based reranking method designed to optimize nugget coverage rather than traditional document relevance for long-form RAG tasks like automated report generation. The core insight is that existing retrieval methods are optimized for relevance ranking, which tends to surface documents with common information while missing diverse facets of complex information needs. LANCER operates in three stages: first generating synthetic sub-questions that decompose the information need, then using an LLM to judge how well each candidate document answers each sub-question (producing a matrix of answerability scores), and finally aggregating these scores using coverage-aware strategies (summation, reciprocal rank fusion, or greedy selection) to produce a reranked list. Evaluations show that LANCER achieves higher α-nDCG and coverage scores than pointwise, listwise, and setwise LLM rerankers while maintaining competitive relevance metrics.
📚 https://arxiv.org/abs/2601.22008
👨🏽💻 https://github.com/DylanJoo/LANCER
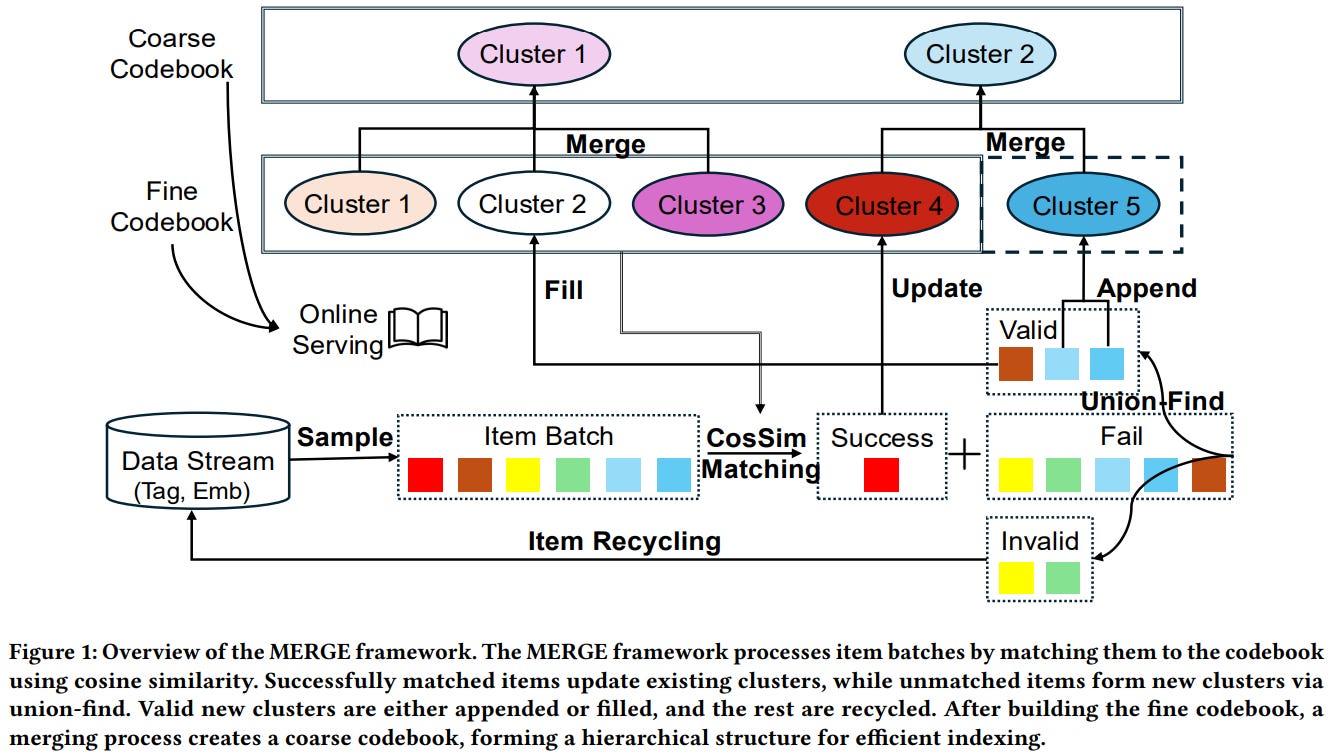
[9] MERGE: Next-Generation Item Indexing Paradigm for Large-Scale Streaming Recommendation
This paper from ByteDance introduces MERGE, an item indexing paradigm designed for large-scale streaming recommendation systems that addresses three fundamental limitations of existing Vector Quantization (VQ)-based approaches:
Poor assignment accuracy: items poorly aligned with assigned clusters, averaging only 0.6 cosine similarity.
Imbalanced cluster occupancy: long-tail items indiscriminately grouped together
Insufficient cluster separation: inter-cluster similarity exceeding 0.5, causing training instability
Unlike VQ methods that rely on predefined cluster counts, MERGE dynamically constructs clusters from scratch using a multi-step process: incoming item batches are matched to existing clusters via cosine similarity with a threshold-based acceptance criterion, successfully matched items update cluster embeddings through Exponential Moving Average, unmatched items form new clusters via Union-Find algorithm, and cluster occupancy is continuously monitored to reset underfilled or stagnant clusters. The framework then builds a hierarchical index structure by merging fine-grained clusters into coarser layers using an affinity-based merging process with silhouette coefficient-based pruning. Offline evaluations on industrial-scale data (hundreds of millions of candidates) demonstrate that MERGE achieves 0.9 mean item-to-cluster cosine similarity versus VQ’s 0.6, produces more uniform cluster sizes (max ~17,500 items versus ~40,000 for VQ), and generates near-zero mean inter-cluster similarity compared to VQ’s 0.6.
📚 https://arxiv.org/abs/2601.20199
[10] PRISM: Purified Representation and Integrated Semantic Modeling for Generative Sequential Recommendation
This paper from Fang et al. introduces PRISM (Purified Representation and Integrated Semantic Modeling) to address two limitations in lightweight Generative Sequential Recommendation (GSR) frameworks: impure/unstable semantic tokenization, where codebook-based quantization suffers from interaction noise contamination and codebook collapse, and lossy/weakly structured generation, where discrete Semantic IDs (SIDs) discard fine-grained continuous information necessary for distinguishing semantically similar items.
The framework introduces a Purified Semantic Quantizer comprising three mechanisms:
Adaptive Collaborative Denoising (ACD) that uses a learned gating network supervised by item popularity to selectively filter unreliable collaborative signals before fusion with content features.
Hierarchical Semantic Anchoring (HSA) that leverages category tags as semantic priors to organize codebook layers in a coarse-to-fine structure matching residual quantization’s nature.
Dual-Head Reconstruction to prevent high-dimensional content embeddings from dominating over collaborative signals during optimization.
Experiments on four Amazon datasets demonstrate PRISM achieves near-optimal codebook utilization (248.5 perplexity vs. TIGER’s 84.2) with minimal collision rates (1.79%), outperforms all baselines across metrics (33.9% Recall@10 improvement over TIGER on CDs), and shows particular strength in sparse/long-tail scenarios while maintaining the lowest inference latency (29.1ms) and smallest parameter count (5.5M) among generative methods through its sparse MoE design.
📚 https://arxiv.org/abs/2601.16556
Extras: Tools
🛠️ OwlerLite: Scope- and Freshness-Aware Web Retrieval for LLM Assistants
OwlerLite is a browser-based RAG system designed to give users explicit control over which web sources are consulted and how up to date the retrieved content is. The tool allows users to define persistent, reusable retrieval scopes over selected web pages and incorporates a freshness-aware crawler that detects semantically meaningful changes in those pages and selectively re-indexes updated content.
📝 https://arxiv.org/abs/2601.17824
👨🏽💻 https://github.com/searchsim-org/owlerlite
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.