
Context Engineering as a Recommendation Problem, Collaborative Retrieval for Personalized RAG, and More!
Vol.157 for May 18 - May 24, 2026

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
A Collaborative Filtering Approach to Context Engineering, from Zhu et al.
Reassessing Matryoshka Representation Learning for Text Encoders, from Takeshita et al.
Fixing BM25 for Code Retrieval, from AgentField
User Lifecycle-Aware Uncertainty Quantification in a Production Recommender, from TikTok
Collaborative Retrieval for Personalized RAG, from Nkhata et al.
A Systematic Analysis of Expansion Term Wackiness in SPLADE, from the University of Tübingen
Measuring Prompt Sensitivity in Embedding Benchmarks, from Kostiuk et al.
LLM-Generated Synthetic Queries and Labels for Cold-Start Natural Language Search, from Airbnb
Transferring LLM World Knowledge into Generative Recommenders, from Alibaba
GPU Acceleration for SQL+VS Workloads, from ETH Zürich
[1] Contexting as Recommendation: Evolutionary Collaborative Filtering for Context Engineering
This paper from Zhu et al. reframes automated context engineering for LLMs as a recommendation problem rather than a global search for one best prompt. The authors observe that different inputs benefit from different guidance, so optimizing a single context strategy across a whole dataset leaves instance-level gains on the table. They propose a framework called Neural Collaborative Context Engineering (NCCE) that treats input instances as “users” and composite context strategies (instruction, few-shot examples, reasoning format, output constraints) as “items,” with observed task accuracy serving as the interaction signal. NCCE works in three stages:
It bootstraps a diverse anchor catalog by clustering training instances via KMeans on semantic embeddings.
Then it enters a Context-CF Co-Evolution loop where a lightweight Neural Collaborative Filtering (NCF) model identifies failure instances, gradient ascent on context embeddings points toward NCF-predicted optima, and the nearest existing context is selected. An LLM reflector mutates it into a new specialized variant that feeds fresh interactions back to the NCF.
At inference, the trained NCF routes each instance to its predicted-best context.
Additional analyses show the NCF is sample-efficient (30% interaction density already captures most of the gain).
📚 https://arxiv.org/abs/2605.15721
👨🏽💻 https://anonymous.4open.science/r/Context_Engineering_Collaborative_Filtering-1EF5
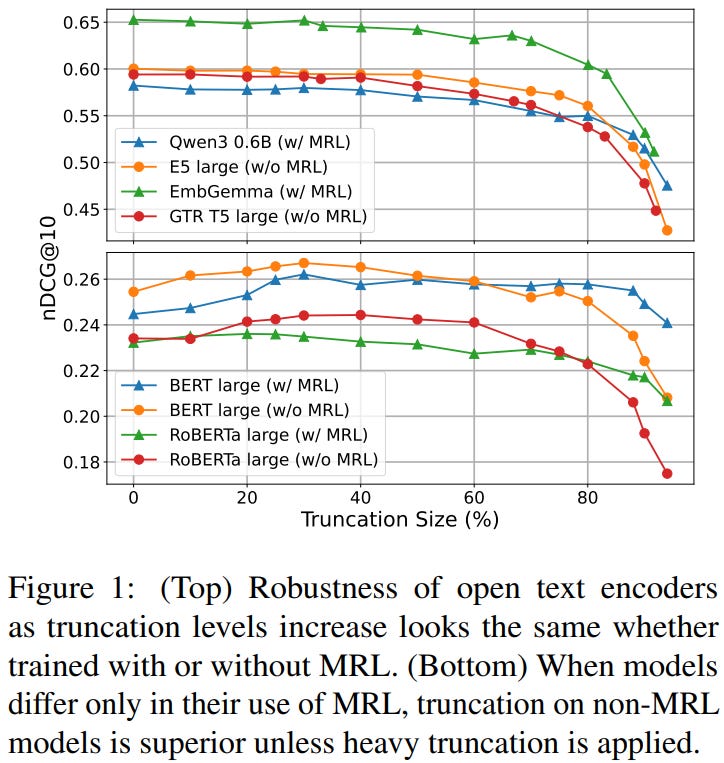
[2] To MRL or not to MRL: Text Embeddings are Robust to Truncation Without Matryoshka Embeddings, Except In Heavy Truncation Scenarios
This paper from Takeshita et al. asks whether Matryoshka Representation Learning (de facto industry standard used in models like Qwen3-Embedding, EmbeddingGemma, and Jina-Embeddings-V5) actually delivers the truncation robustness it is credited with, or whether plain text embeddings are already robust enough that the extra work is unnecessary. Prior work showed that simply chopping off the tail of an embedding vector causes little performance loss until roughly 70% of dimensions are removed. But the authors directly pit this random truncation against MRL. They run two experiments. First, they benchmark eight off-the-shelf encoders (four around 500M parameters, four around 4B) on 13 NanoBEIR retrieval tasks and 11 MTEB classification tasks, applying deterministic tail truncation at MRL-aligned sizes (64, 128, 256, 512, 768) and at 10%-step relative positions. Second, to control for confounders like architecture and training recipe, they train matched pairs of BERT (base/large), RoBERTa (base/large), and T5-base encoders with multiple negative ranking loss on SNLI+MultiNLI, with and without MRL on nested dimensions {64, 128, 256, 512, 768}. The pattern is consistent across both settings: up to about 80% truncation, non-MRL embeddings match or beat their MRL counterparts, and MRL only pulls ahead under heavy truncation. Inspecting the trained encoders, they find that MRL drives noticeably higher variance in the low-index dimensions, evidence that the objective genuinely concentrates information into early coordinates, though it remains unclear why this benefit doesn’t carry across all truncation levels. Their takeaway is that the truncation robustness is largely inherent to learned text representations rather than a gift from MRL. Also, MRL’s added training cost is justified mainly when you plan to slash embedding size by 80% or more, and MRL behaves like random truncation when you cut at dimensions outside its pre-selected set, leaving room for future variants that extend its benefits across the full truncation range.
📚 https://arxiv.org/abs/2605.16608
👨🏽💻 https://github.com/sobamchan/mrl-or-random
[3] Improving BM25 Code Retrieval Under Fixed Generic Tokenization: Adaptive q-Log Odds as a Drop-In BM25 Fix
This paper from AgentField tackles a specific failure mode in code retrieval: when BM25 runs on top of a generic tokenizer, its logarithmic RSJ-odds IDF fails to separate rare identifiers from merely uncommon ones, so the gold file gets buried under distractors sharing a few middle-frequency tokens. The fix is a one-line substitution that replaces the outer logarithm with the Tsallis q-logarithm, lnq(x) = (x^(1−q) − 1)/(1 − q), which is mathematically a Box-Cox transform of the RSJ odds at λ = 1 − q and recovers BM25 exactly at q = 1. On CoIR CodeSearchNet Go (182K docs), oracle-tuned NDCG@10 jumps from 0.2575 to 0.4874 (+89.3%, zero sign reversals across 10,000 paired-bootstrap resamples), with graded gains across other code languages, near-zero deltas on BEIR text, and a monotone scaling curve from 1K to 182K. Further, their tokenizer ablation finds that identifier-aware analyzers that emit both whole identifiers and sub-tokens absorb most of the q-IDF gain, so the method’s real niche is the frozen-tokenizer regime common in managed Elasticsearch, Lucene, and Tantivy deployments, where index-time cost is one sparse-matrix rescale and query latency is unchanged.
📚 https://arxiv.org/abs/2605.18561
👨🏽💻 https://github.com/santoshkumarradha/rarecode
[4] Uncertainty-Calibrated Recommendations for Low-Active Users
This paper from TikTok addresses a problem in industrial recommenders where most deep models output point predictions with no notion of confidence, and the standard fixes either cost too much (MC dropout, full Bayesian inference) or are too coarse (global conformal intervals, temperature scaling) to drive per-user-per-item decisions in a low-latency ranking stack. The authors build a unified, production-ready uncertainty layer with two complementary heads sharing a DCN backbone: an auxiliary critic network trained on realized errors from rolling daily checkpoints, and an empirical-Bayes head that emits an input-dependent Beta prior. Raw scores are converted to actionable thresholds by quantile calibration on a hold-out set, then routed through a segment-aware dual policy. Risk-averse deboosting is utilized for Low-Active Users, who churn easily under unreliable predictions, and a UCB-style exploration bonus is used for High-Active Users. A 14-day A/B test on production livestream traffic shows the unified critic-plus-Bayes setup beats Multi-head Ensemble, MC Dropout, and a matched random-deboost control.
📚 https://arxiv.org/abs/2605.17788
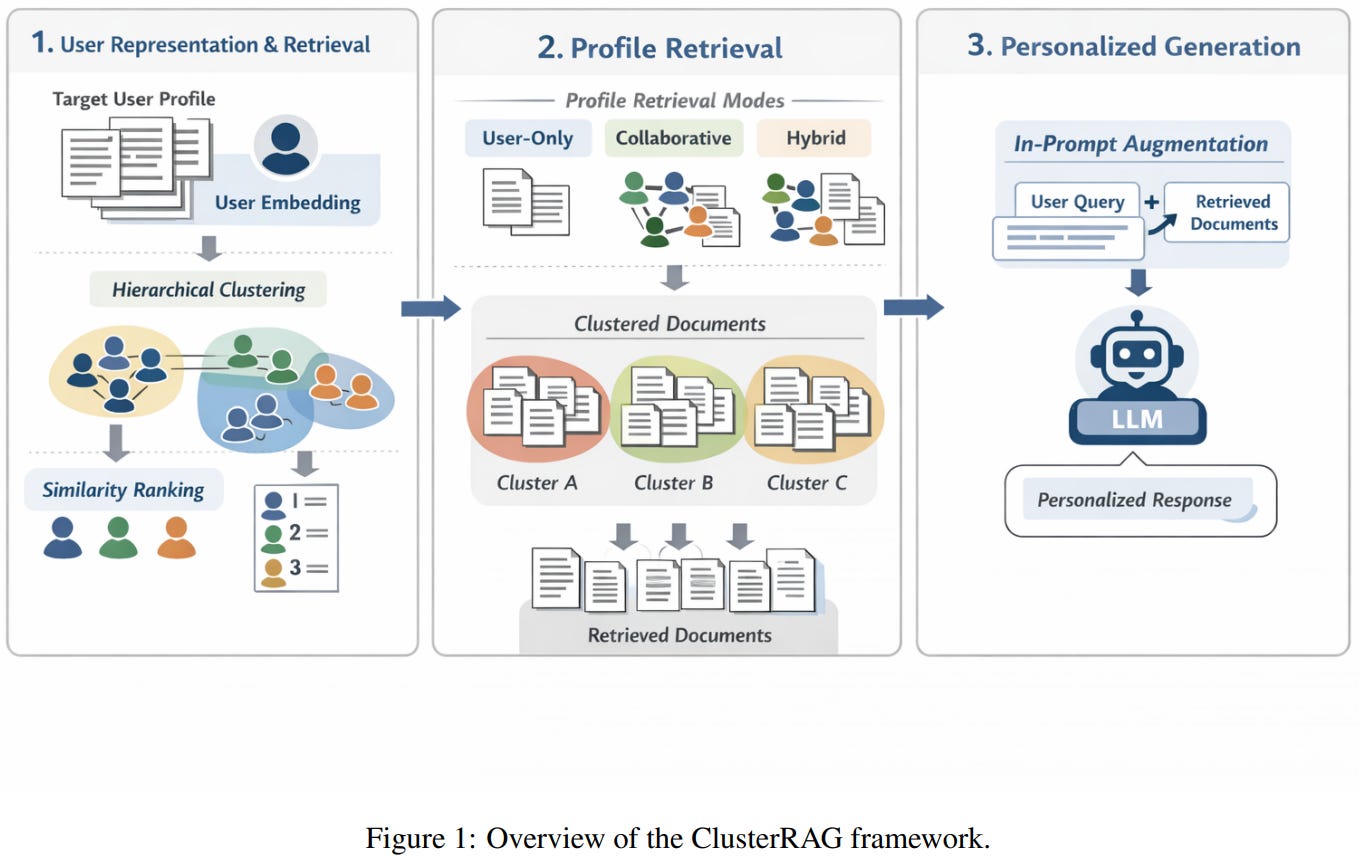
[5] ClusterRAG: Cluster-Based Collaborative Filtering for Personalized Retrieval-Augmented Generation
This paper from Nkhata et al. presents ClusterRAG, a personalized RAG framework that uses collaborative filtering to enrich a target user’s profile with signals from similar users. The method first builds compact user embeddings by averaging ColBERTv2 encodings of each user’s profile documents, then groups users into cohorts with HDBSCAN density-based clustering and ranks intra-cluster neighbors using a ColBERTv2 similarity matrix. At query time, candidate documents come from one of three modes (user-only, collaborative, or hybrid), get clustered again for topical organization, and are retrieved through a two-stage process that first selects the top centroids and then reranks documents within those clusters. The retrieved documents feed into the LLM via In-Prompt Augmentation with a tunable mixing parameter balancing query and profile length. On the LaMP benchmark across six tasks, the hybrid variant beats every baseline, including CFRAG and LaMP-IPA. The framework holds up across dense, sparse, and heuristic retrievers and works with both fine-tuned FlanT5-base and zero-shot FlanT5-XXL and Qwen2-7B-Instruct.
📚 https://arxiv.org/abs/2605.18769
👨🏽💻 https://github.com/academicprojects44/anonymous
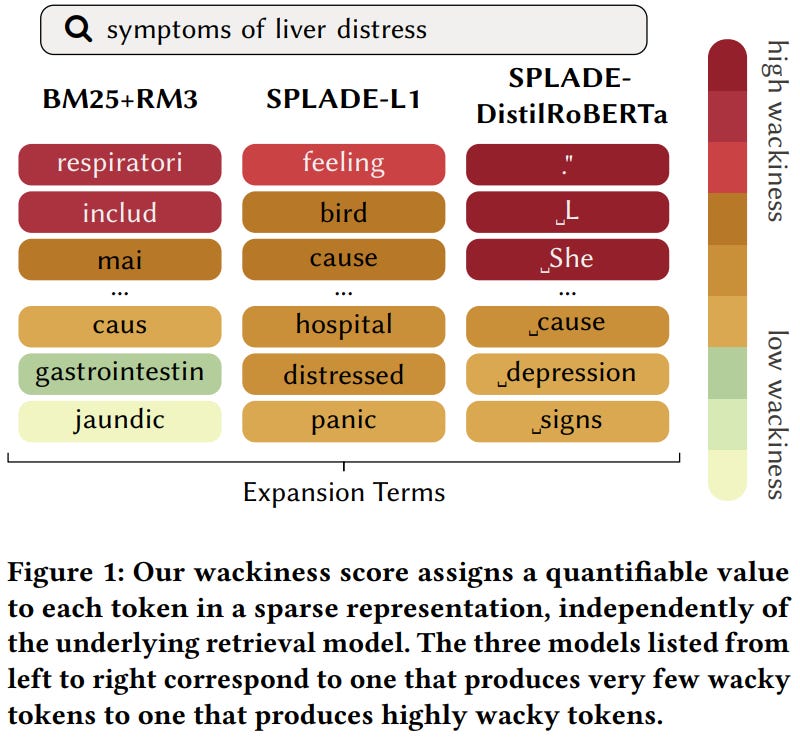
[6] Understanding Wacky Weights: A Dissection of SPLADE’s Learned Term Importance
This paper from the University of Tübingen takes the “wacky weights” phenomenon in SPLADE, where the model assigns high importance to expansion terms that look semantically unrelated to the input, and turns it into something measurable. The authors define a token as wacky if it is produced during expansion (not in the original input) and has low TF-IDF importance within the documents retrieved for that input, which gives them a per-token Wackiness Score. To compare models with different vocabularies and sparsity levels, they bin rank tokens by vocabulary percentage and build a Normalized Wackiness Curve summarized by W-AUC. They reproduce SPLADE-v2 and train variants that swap the backbone (DistilBERT, DistilRoBERTa, ModernBERT), the sparsity regularizer (FLOPs vs L1), the aggregation function (MAX, SUM, CLS), and the fine-tuning dataset (MS MARCO vs Natural Questions), then ablate wacky tokens at various thresholds against a random-removal baseline. Three findings come out:
SPLADE-v3 leans heavily on wacky tokens for in-domain MS MARCO effectiveness (especially Recall@10) while SPLADE-v2 does not, and on BEIR removal barely matters for either, suggesting these tokens encode dataset-specific ranking signals rather than transferable semantics.
Larger vocabularies (ModernBERT, DistilRoBERTa) inflate wackiness while L1 regularization suppresses it relative to FLOPs.
Qualitatively, minor architectural tweaks keep the wacky vocabulary anchored on proper names and stopwords, whereas changing the dataset or backbone shifts it toward non-Latin characters or tokenizer artifacts.
The broader takeaway is that LSR’s claim to interpretability-by-design doesn’t really hold, since wacky tokens are load-bearing for effectiveness but disconnected from human-aligned semantics.
📚 https://arxiv.org/abs/2605.19628
👨🏽💻 https://github.com/polgrisha/understanding-wacky-weights
[7] One prompt is not enough: Instruction Sensitivity Undermines Embedding Model Evaluation
This paper from Kostiuk et al. argues that the standard practice of evaluating instruction-tuned embedding models with a single prompt per task hides a critical weakness: these models are highly sensitive to how the instruction is phrased. To show this, they tested 6 open-weight embedding models (including Qwen3-Embedding-0.6B, multilingual-e5-large-instruct, KaLM-mini-v2.5, and the BGE small/base/large family) on 11 MTEB/MMTEB tasks spanning retrieval, classification, clustering, and STS, using 15 GPT-OSS-120B-generated task-specific prompts per dataset for 990 evaluations total. The reported MTEB scores often fail to match the distribution of plausible-prompt results, sometimes landing in the lower tail (prompt deflation) and sometimes in the upper tail (prompt inflation). Rankings also prove fragile: by giving a target model its best prompt while competitors use their defaults or worst prompts, the authors push every model in the study, even bge-small, to first place on an aggregated Borda leaderboard, and even the milder “best-vs-default” setup moves bge-large from 5th to 3rd. They label this selective reporting “prompt hacking” (which can also happen without bad intent), and recommend that benchmarks shift to multi-prompt evaluation or report robustness metrics alongside point estimates, while model developers either train for prompt robustness or commit to constrained prompt schemes like Jina v5’s.
📚 https://arxiv.org/abs/2605.22544
👨🏽💻 https://github.com/centre-for-humanities-computing/instruction-sensitivity-evaluation
[8] Bridging the Cold-Start Gap: LLM-Powered Synthetic Data Generation for Natural Language Search at Airbnb
This paper from Airbnb tackles the cold-start problem of launching natural language search on a platform with no real user queries and no relevance labels to train ranking models. Their framework uses LLMs to manufacture both synthetic queries and topicality labels at production scale, starting from roughly 500 seed queries gathered through user research surveys. The query generation pipeline samples contrastive listing pairs from real booking sessions (a booked listing as positive, a less-engaged listing from the same search as negative), enriches them with catalog features like amenities, reviews, and pricing, then prompts an LLM to write a query where one listing is more topically relevant than the other, yielding labeled triplets by construction. Against a baseline that uses contrastive pairs without seed guidance, the seed-guided approach cuts KL divergence on query length from 4.95 to 0.66 (a 7.5x improvement) versus real users, and hits 0.04 KL on attribute-type distribution, beating even the seed queries themselves at 0.09. The pipeline runs daily in production, generating about 10,000 examples per batch with an 80/20 seed-guided to variety mix, and the authors frame it as a bridge from cold to warm start where real query data progressively replaces survey seeds as traffic accumulates.
📚 https://arxiv.org/abs/2605.21812
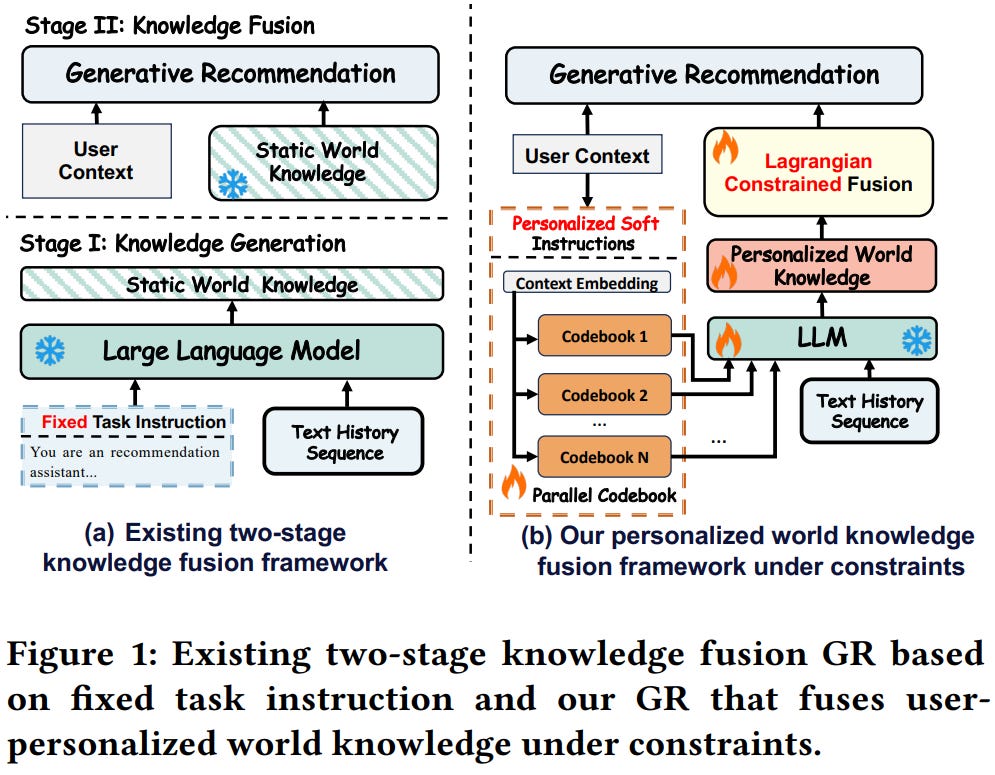
[9] LWGR: Lagrangian-Constrained Personalized World Knowledge for Generative Recommendation
This paper from Alibaba introduces LWGR, a framework for injecting LLM world knowledge into generative recommendations. The work is motivated by two pilot findings: fixed prompts can’t match heterogeneous user interests, and naive knowledge fusion sometimes hurts performance. On the extraction side, the authors learn personalized “soft instructions” rather than hand-written prompts. They mean-pool the user context vector from a GR encoder, project it into K subspaces, and quantize each via a parallel codebook using an IBQ-style straight-through estimator. The resulting K embeddings are prepended to the user’s tokenized item history and passed through a frozen or LoRA-adapted LLM (Qwen3, 0.6B–8B) to produce a knowledge tensor. On the fusion side, this tensor enters the decoder through cross-attention on the [BOS] token, so the prior influences the full autoregressive SID generation. To stop harmful knowledge from degrading the base recommender, training is cast as a constrained optimization: the average per-sample drop in mean token log-probability of the ground-truth SID, relative to a frozen reference GR, must stay below a tolerance ε. Across Amazon Beauty, Toys, and a 2.95B-interaction industrial dataset, LWGR beats eight baselines (SASRec, PinnerFormer, HeterRec, VQ-Rec, TIGER, Cobra, TIGER+KAR, TIGER+SeRALM). A two-week A/B test delivered a 1.35% revenue lift, 0.83% GMV gain, and 1.17% CTR gain.
📚 https://arxiv.org/abs/2605.18771
[10] To GPU or Not to GPU: Vector Search in Relational Engines
This paper from ETH Zürich asks a simple question: should relational databases run vector search on GPUs the way ML systems do, or stick with CPUs as most DBMS+VS engines currently do? To answer it, the authors build Vec-H, a benchmark extending TPC-H with two embedding tables and eight queries that mix SQL operators with vector search in various plan positions, plus MaxVec, an execution engine that can place each operator on CPU or GPU independently and handle data movement transparently. They test across PCIe 5.0, NVLink-C2C, and a unified-memory DGX Spark system. Their findings are counterintuitive. Most of the GPU speedup on these mixed workloads comes from accelerating the relational operators, not the vector search; in fact, relational operators are often orders of magnitude more expensive than the search itself. Worse, the data-owning indexes used in every current DBMS+VS make GPU vector search a losing proposition even on fast interconnects, because moving the index drags along all the embeddings, and the transfer machinery is poorly optimized. The authors propose decoupling the index structure from the embedding storage, so only the small search structure moves to the GPU. With that change, running both halves of the query on the GPU becomes the best option. They distill the results into a decision heuristic for when to use full-GPU, hybrid, or index-only-on-GPU execution depending on index type and memory budget, and note that unified-memory appliances like DGX Spark sidestep the placement question entirely, which they suggest is a promising direction for database hardware.
📚 https://arxiv.org/abs/2605.15957
👨🏽💻 https://github.com/mageirakos/vec-h
Extras: Benchmarks
⏱️ RecoAtlas: From Semantic Plausibility to Set-Level Utility in LLM Recommendation Agents
RecoAtlas is a benchmark and evaluation framework for LLM-based recommendation agents that generate multi-item shopping reports rather than ranked lists. It evaluates agents in large-catalog comparative-shopping and bundle-shopping scenarios where models must search for products, use recommendation-oriented tools, and assemble coherent recommendation sets with natural-language justifications.
📝 https://arxiv.org/abs/2605.18805
👨🏽💻 https://github.com/imadaouali/reco-atlas
🤗 https://huggingface.co/iaouali/reco-atlas
⏱️ DeepWeb-Bench: A Deep Research Benchmark Demanding Massive Cross-Source Evidence and Long-Horizon Derivation
DEEPWEB-BENCH is a benchmark for evaluating deep research agents on open-web information retrieval and multi-step analytical tasks. The benchmark contains 100 domain-specific tasks structured as 8×8 matrices of entities and analytical dimensions, yielding 6,400 independently scored cells.
📝 https://arxiv.org/abs/2605.21482
👨🏽💻 https://sixiongxie1001-dot.github.io/deep-research-benchmark2.0/
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.