
Bridging the Gap Between Text-Only and Multimodal Retrieval, The Case for Corpus Expansion in RAG and More!
Vol.125 for Oct 06 - Oct 12, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
A 3B Parameter Unified Embedding Model for Cross-Modal Retrieval Across Text, Image, Audio, and Video, from NVIDIA
Exploiting Attention Sparsity for Efficient In-Context Document Ranking, from Google DeepMind
Corpus Scaling as a Substitute for Model Scaling in Retrieval-Augmented Generation, from CMU
A Framework for Adapting Pre-trained Language Models to Industrial-Scale Generative Recommendation, from YouTube
Embedding Generation via Chain-of-Thought in Large Language Models, from CUHK
Controlled Analysis of Context Length Effects on LLM Performance Under Perfect Retrieval Conditions, from Du et al.
A Think-Then-Embed Framework for Multimodal Retrieval, from Meta
A Model-Agnostic Approach to Long-Tail Item Recommendation Through Strategic Sampling, from Alshabanah et al.
A Deployable Search Agent Framework for Knowledge-Intensive Question Answering, from Alibaba
Decoupling Search and Reasoning in Language Model Agents, from Wang et al.
[1] Omni-Embed-Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video
This paper from NVIDIA presents Omni-Embed-Nemotron, a unified multimodal retrieval model that extends retrieval capabilities beyond traditional text-based systems to handle text, images, audio, and video within a single embedding model. Built on the Qwen-Omni/Qwen2.5-Omni-3B foundation and utilizing a bi-encoder architecture, the model supports both cross-modal retrieval (e.g., text→video) and joint-modal retrieval (e.g., text+audio→video+image). A key architectural distinction from Qwen-Omni is the separate encoding of audio and video streams rather than interleaving tokens, which the authors found improves retrieval performance by preserving each modality’s complete temporal context. The model employs contrastive learning with InfoNCE loss and hard negative mining, while freezing audio and visual encoders and applying LoRA tuning only to the language model backbone. Training utilized text-text and text-image pairs from datasets including ColPali, Wiki-SS-NQ, and Docmatix, with optional fine-tuning on FineVideo for video-specific tasks. Evaluations demonstrate that multimodal retrieval provides clear advantages for open-domain video content where transcripts may be noisy, though text-specialized models retain slight edges in text-centric scenarios like lecture videos with high-quality transcripts.
📚 https://arxiv.org/abs/2510.03458
[2] Scalable In-context Ranking with Generative Models
This paper from Google DeepMind presents BlockRank to address the computational inefficiency of In-Context Ranking (ICR), where LLMs process queries alongside candidate documents to identify relevant results, a paradigm that suffers from quadratic attention complexity as candidate lists grow. Through analysis of attention patterns in fine-tuned Mistral-7B on MSMarco, the authors identify two exploitable structures: inter-document block sparsity (where document tokens attend primarily within their own blocks rather than across all documents) and query-document block relevance (where specific query tokens in middle layers strongly attend to relevant documents). Leveraging these insights, BlockRank implements structured sparse attention that constrains document tokens to attend only to their own content and instruction tokens while allowing query tokens full context access, reducing complexity from quadratic to linear. The method incorporates an auxiliary contrastive loss (InfoNCE) applied at a middle layer to explicitly optimize attention from signal-carrying query tokens toward relevant documents, enabling efficient attention-based inference that bypasses auto-regressive decoding.
📚 https://arxiv.org/abs/2510.05396
[3] Less LLM, More Documents: Searching for Improved RAG
This paper from CMU investigates whether expanding retrieval corpora can compensate for using smaller language models in RAG systems. The researchers conducted systematic experiments using the Qwen3 model family (ranging from 0.6B to 14B parameters) paired with varying corpus sizes from ClueWeb22, evaluated on Natural Questions, TriviaQA, and WebQuestions benchmarks. Their findings demonstrate that corpus scaling consistently improves RAG performance and can effectively substitute for larger models. For instance, a 4B model with a 2× larger corpus outperforms an 8B model with the baseline corpus. The improvements stem primarily from increased coverage of answer-bearing passages rather than enhanced utilization efficiency, which remains relatively stable across model sizes and corpus scales. Mid-sized models (1.7B-4B parameters) showed the highest utilization ratios, benefiting most from corpus expansion, while very small models required disproportionately large corpus increases and very large models showed diminishing returns. Performance gains saturate after approximately 5-6x corpus expansion, indicating clear limits to this approach. These results establish a practical corpus-generator trade-off for resource-constrained deployments, suggesting that investing in larger retrieval corpora offers a viable alternative to deploying LLMs.
📚 https://arxiv.org/abs/2510.02657
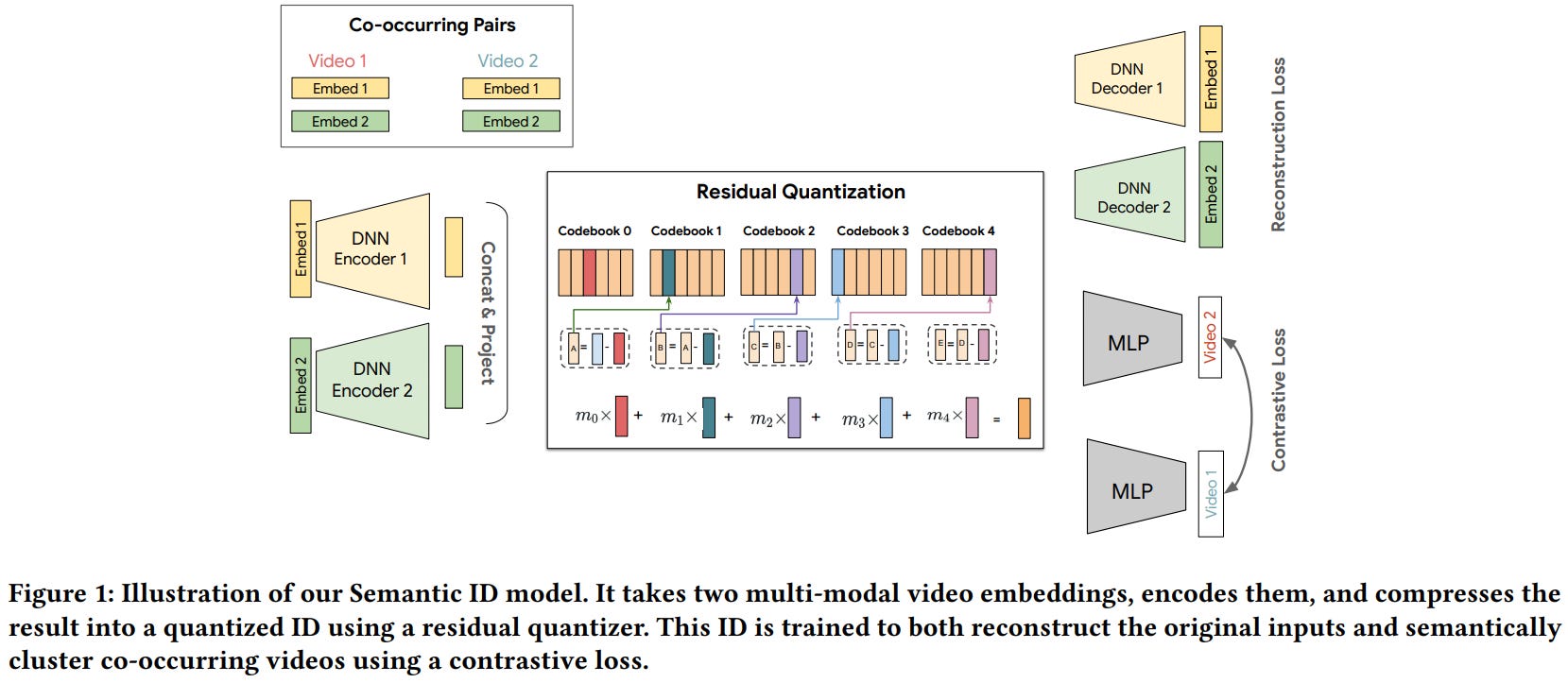
[4] PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
This paper from YouTube introduces PLUM, a framework for adapting pre-trained LLMs to industrial-scale generative recommendation systems, specifically deployed on YouTube. The framework consists of three key stages: (1) item tokenization using enhanced Semantic IDs (SID-v2) that incorporate multi-modal content embeddings, collaborative filtering signals through co-occurrence contrastive learning, and hierarchical improvements via multi-resolution codebooks and progressive masking; (2) continued pre-training that expands the LLM vocabulary to include SID tokens and trains on domain-specific user behavior data mixed with video metadata to align the new modality with existing model knowledge; and (3) task-specific fine-tuning for generative retrieval, where the model autoregressively generates SIDs of recommended items without requiring separate item indexes. Experiments on YouTube’s production data demonstrate that PLUM-based retrieval substantially outperforms heavily optimized large embedding models, achieving 2.6-13.2x larger effective vocabulary sizes while maintaining competitive engagement metrics and requiring significantly fewer training examples (less than 0.55× FLOPs).
📚 https://arxiv.org/abs/2510.07784
[5] Search-R3: Unifying Reasoning and Embedding Generation in Large Language Models
This paper from CUHK presents Search-R3, a framework that enables LLMs to generate high-quality search embeddings directly through their reasoning processes, addressing the disconnect between LLM capabilities and embedding generation. The approach employs a two-stage training pipeline: first, supervised fine-tuning with contrastive learning teaches the model to produce embeddings via a special <|embed_token|> without architectural modifications; second, reinforcement learning using Group Relative Policy Optimization (GRPO) optimizes both reasoning quality and embedding effectiveness through an end-to-end retrieval environment. A key innovation is the scalable RL environment that uses selective graph updates, refreshing only neighborhoods around query-relevant documents rather than re-encoding entire corpora, making large-scale training computationally feasible. The method leverages chain-of-thought reasoning, prompting the model to analyze queries step-by-step before generating embeddings, thereby integrating semantic understanding with explicit logical analysis. Evaluations demonstrate substantial improvements over existing embedding models, with particularly strong gains when reasoning is enabled.
📚 https://arxiv.org/abs/2510.07048
👨🏽💻 https://github.com/ytgui/Search-R3

[6] Context Length Alone Hurts LLM Performance Despite Perfect Retrieval
This paper from Du et al. challenges a fundamental assumption in long-context LLM research by demonstrating that even with perfect retrieval, i.e., where models can recite evidence with 100% exact match, performance still degrades substantially (13.9%–85%) as input length increases. Through systematic experiments across 5 models (including Llama-3.1, Mistral, GPT-4o, Claude-3.5, and Gemini-2.0) on math, question answering, and coding tasks, the authors reveal that this degradation persists even when irrelevant tokens are replaced with minimally distracting whitespace, when evidence is positioned optimally (at the beginning or immediately before questions), and most surprisingly, when all distraction tokens are completely masked out through attention manipulation. The findings demonstrate that sheer context length itself fundamentally impairs LLM reasoning capabilities within their claimed context windows, independent of retrieval quality or token-level distraction. This challenges the prevailing two-part decomposition of long-context tasks into retrieval and reasoning, suggesting that improvements in retrieval alone cannot guarantee better long-context performance. The authors propose a simple “retrieve-then-reason” mitigation strategy that converts long-context tasks into short-context ones by prompting models to first recite evidence, then solve problems in a new shortened context. The paper calls for a holistic evaluation of long-context capabilities beyond retrieval-focused metrics and offers explanations for recurring observations in RAG systems where performance saturates or degrades with additional context.
📚 https://arxiv.org/abs/2510.05381
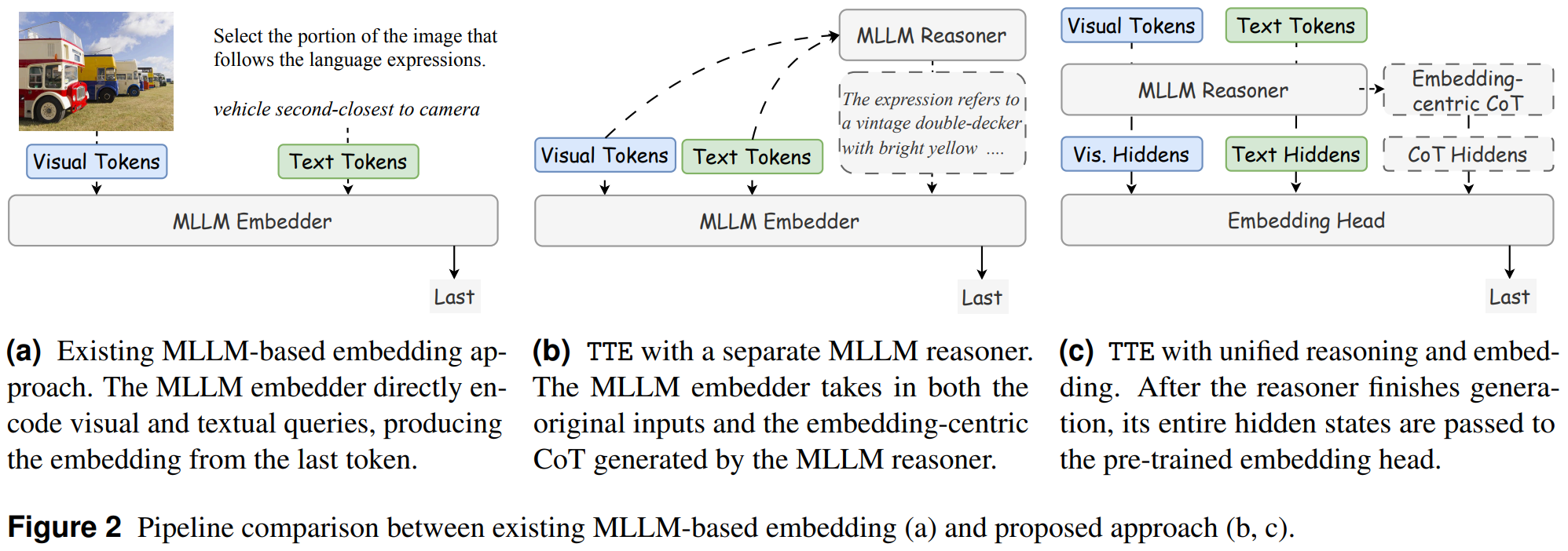
[7] Think Then Embed: Generative Context Improves Multimodal Embedding
This paper from Meta introduces Think-Then-Embed (TTE), a framework that enhances multimodal embedding models by incorporating explicit chain-of-thought reasoning before generating embeddings. The authors argue that existing Multimodal Large Language Models (MLLMs) used for Universal Multimodal Embeddings treat these models solely as encoders, overlooking their generative capabilities. This limitation becomes problematic for complex instructions requiring compositional reasoning. TTE addresses this by using a reasoner MLLM to first generate Embedding-Centric Reasoning (ECR) traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original input and the reasoning. The framework is evaluated in three variants: TTEt uses a large teacher reasoner (Qwen2.5-72B), TTEs employs a finetuned smaller reasoner distilled from the teacher, and TTEu unifies reasoning and embedding in a single model with a pluggable embedding head. Experimental results on MMEB-V1 and MMEB-V2 benchmarks demonstrate that TTEt achieves state-of-the-art performance (71.5% on MMEB-V2), surpassing proprietary models, while TTEs attains the best performance among open-source models with a 7% absolute improvement, and TTEu offers efficiency gains by halving parameters without sacrificing performance.
📚 https://arxiv.org/abs/2510.05014
[8] The Upside of Bias: Personalizing Long-Tail Item Recommendations with Biased Sampling
This paper from Alshabanah et al. introduces Biased User History Synthesis (BUHS), a model-agnostic training framework that addresses the long-tail item recommendation problem in recommendation systems by strategically sampling tail items from user interaction histories to augment user representations. The approach uses a temperature-controlled softmax distribution to bias sampling toward less popular items, then employs one of three synthesis models (Mean, User-Attention, or GRU) to combine sampled item representations with base user embeddings, creating more personalized representations that improve recommendations for both head and tail items. The authors provide theoretical justification through an information-theoretic analysis showing that tail items in a user’s history carry more pointwise mutual information about user identity than popular items, explaining why biased sampling enhances personalization. Experimental results demonstrate that BUHS variants achieve substantial improvements over state-of-the-art baselines, including meta-learning approaches, loss correction techniques, and graph-based methods. Additional analysis reveals that BUHS maintains fairness across different user groups, requires minimal computational overhead during training, and can be effectively applied to various base recommendation architectures, including Two Tower Neural Networks, Wide & Deep, and DeepFM, making it a practical solution for improving recommendation diversity and personalization without requiring additional training data or architectural modifications.
📚 https://dl.acm.org/doi/10.1145/3771279
👨🏽💻 https://github.com/lkp411/BiasedUserHistorySynthesis
[9] QAgent: A modular Search Agent with Interactive Query Understanding
This paper from Alibaba introduces QAgent, a modular search agent framework designed to improve RAG systems through enhanced query understanding. The authors address two key limitations of existing RAG approaches: (1) traditional RAG struggles with complex query understanding, and (2) search agents trained with reinforcement learning (RL) face generalization and deployment challenges. QAgent employs a multi-turn interaction loop where the agent iteratively refines queries through planning, searching, and reflection, framing the process as a sequential decision-making problem optimized via RL. The authors propose a two-stage training strategy: the first stage uses end-to-end RL to jointly optimize retrieval and generation, while the second stage focuses specifically on retrieval quality by using a frozen generator to calculate rewards, thereby preventing reward hacking and improving generalization when deployed as a plug-and-play submodule in complex systems.
📚 https://arxiv.org/abs/2510.08383
👨🏽💻 https://github.com/OpenStellarTeam/QAgent
[10] Beyond Outcome Reward: Decoupling Search and Answering Improves LLM Agents
This paper from Wang et al. introduces DeSA (Decoupling Search-and-Answering), a two-stage reinforcement learning framework for training search-augmented language model agents. The authors challenge the common assumption that optimizing agents solely on outcome-based rewards (like exact match accuracy) will implicitly teach effective search behaviors. Through systematic analysis of agents trained with outcome-only rewards, they identify critical deficiencies, including failure to invoke search tools, invalid queries, and redundant searches. DeSA addresses these issues by explicitly separating training into two stages: Stage 1 focuses on search skill acquisition using retrieval recall-based rewards to develop effective information-seeking behaviors, while Stage 2 employs outcome rewards to optimize answer generation from retrieved evidence. Experiments across seven question-answering benchmarks using Qwen2.5-3B and 7B models demonstrate that DeSA substantially outperforms single-stage outcome-only training. The results underscore that explicitly decoupling search optimization from answer generation is more effective than relying on outcome rewards alone or simultaneously optimizing both objectives.
📚 https://arxiv.org/abs/2510.04695
👨🏽💻 https://github.com/yiding-w/DeSA
Extras: Benchmarks
⏱️ UNIDOC-BENCH: A Unified Benchmark for Document-Centric Multimodal RAG
UniDoc-Bench is a large-scale benchmark introduced to evaluate document-centric multimodal RAG systems. It consists of 70,000 real-world PDF pages spanning eight domains and 1,600 multimodal question–answer pairs grounded in text, figures, and tables. The dataset supports four task types: factual retrieval, comparison, summarization, and logical reasoning, and allows standardized evaluation across text-only, image-only, multimodal text–image fusion, and multimodal joint retrieval setups.
📝 https://arxiv.org/abs/2510.03663
👨🏽💻 https://github.com/SalesforceAIResearch/UniDOC-Bench
⏱️ Finding Diamonds in Conversation Haystacks: A Benchmark for Conversational Data Retrieval
The Conversational Data Retrieval (CDR) is a large-scale evaluation framework for retrieving conversation data aimed at deriving product insights. It contains 1,583 queries and 9,146 conversations spanning five analytical areas: Intent & Purpose, Emotion & Feedback, Conversation Dynamics, Trust & Safety, and Linguistic Style. The benchmark combines filtered open-source dialogue datasets with synthetically aligned conversations validated by human experts and large language models.
📝 https://arxiv.org/abs/2510.02938
👨🏽💻 https://github.com/l-yohai/CDR-Benchmark
⏱️ Haystack Engineering: Context Engineering for Heterogeneous and Agentic Long-Context Evaluation
HaystackCraft is a new “needle-in-a-haystack” (NIAH) benchmark designed to evaluate long-context robustness in LLMs under more realistic and agentic conditions. Built on the full English Wikipedia hyperlink network with multi-hop questions, HaystackCraft examines how different retrieval strategies affect distractor composition, context ordering, and model performance. It extends evaluation to dynamic, LLM-dependent settings where models refine queries, reflect on prior reasoning, and decide when to stop.
📝 https://arxiv.org/abs/2510.07414
👨🏽💻 https://github.com/Graph-COM/HaystackCraft
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.