
Bridging Multi-Vector and Learned-Sparse Retrieval, A Diagnostic Framework for Robust Semantic IDs, and More!
Vol.159 for Jun 01 - Jun 07, 2026

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Turning Multi-Vector Retrieval into a Sparse Index, from JHU
Beyond Recall@k: Evaluating ANN Search by Approximation Ratio, from Dimitropoulos et al.
A Diagnostic Framework for Robust Semantic IDs, from Shopee
Inference-Free Multimodal Sparse Retrieval for Visual Documents, from Naver
Treating Semantic IDs as a First-Class Modality in LLM Recommenders, from Pinterest
Position-Level Confidence Estimation for Trustworthy LLM Ranking, from Xidian University
Unifying Generative Retrieval and Ranking in Production, from Pinterest
Reinforcement Learning for Search Agents with State-Externalizing Harnesses, from Jiang et al.
How Annotation Bias Shapes What Retrievers Find, from Valentini et al.
Cost-Aware Evidence Selection in RAG, from Wu et al.
[1] ColBERTSaR: Sparsified ColBERT Index via Product Quantization
This paper from JHU introduces ColBERTSaR (Sparsified ColBERT Index via Product Quantization). In ColBERT-style retrieval, the index is huge, often five to ten times the size of the raw text, mostly because it stores compressed residual vectors for every document token. The authors show that if you drop the residuals and keep only the cluster assignments from product quantization, ColBERT’s MaxSim scoring collapses into something mathematically equivalent to learned-sparse retrieval, with the query-to-centroid dot products acting like query-specific term weights over a sparse vocabulary of anchors. This lets them store the index as a true inverted index plus a lightweight forward index, skipping the expensive gather-and-decompress step entirely. They also propose ways to fit the K-means anchors that directly minimize the MaxSim approximation error rather than just residual magnitude, including an unsupervised variant that uses in-batch document tokens as stand-in queries when no query logs are available. Across monolingual (BEIR), cross-language, and multilingual benchmarks, ColBERTSaR comes in 50 to 70% smaller than a one-bit PLAID index while holding roughly 89 to 92% of PLAID’s effectiveness, with the biggest drops on entity-heavy QA tasks where centroid mapping blurs token meaning (partly recoverable by fusing with BM25).
📚 https://arxiv.org/abs/2606.05568
👨🏽💻 https://github.com/hltcoe/ColBERTSaR
[2] ANN Search: Recall What Matters
This paper from Dimitropoulos et al. argues that Recall@k measures the wrong thing: identifier overlap with the true kNN set rather than the actual quality of what gets retrieved. The authors propose 1/Ratio@k, the inverse approximation ratio, which averages per-position distance ratios between an algorithm’s returned neighbors and the true neighbors. It’s judge-free, hyperparameter-free, and computable from exactly the inputs standard ANN benchmarks already supply, unlike prior alternatives such as Semantic Recall, Tolerant Recall, etc., each of which needs an external judge, a tunable parameter, or extra source data. From a geometric perspective, as intrinsic dimensionality (LID) or k grows, distances to successive neighbors concentrate, so an algorithm routinely returns points just as close as the true neighbors but with different IDs, which drops Recall while 1/Ratio stays high. By benchmarking five algorithms (Annoy, SuCo, HNSW, RaBitQ, SymphonyQG) across six datasets, they show that hitting a fixed quality threshold under Recall costs far more than under 1/Ratio. At T=0.95 and k=100, Recall demands 1.86x to 9.36x more distance computations and roughly 3.27x lower QPS on average, with the gap widening as k and LID rise. Importantly, the advantage is computational. Since memory is dominated by the base index, and algorithm rankings stay essentially stable, existing Recall-based comparative conclusions still hold and can simply be reproduced more cheaply. They then validate that low Recall doesn’t actually hurt downstream work. Across image classification and RAG, quality stays flat as Recall falls to 0.4, and 1/Ratio tracks true quality with prediction error under 3% against Recall’s 25-30%.
📚 https://arxiv.org/abs/2606.04522

[3] Decoupled Residual Quantization for Robust Semantic IDs in Recommendation
This paper from Shopee tackles a basic problem in recommendation systems: when you compress item embeddings into discrete Semantic IDs, it’s hard to diagnose why a given tokenizer underperforms. The authors propose two metrics to make this measurable. The Expected Overlap Rate (O_π) captures how much codeword densities blur together when retrieval-time noise perturbs an item’s latent vector, and the Effective Codebook Size (K_eff = 1/O_π) translates that confusion into the number of genuinely usable, well-separated codes. They further decompose O_π into a distribution penalty (caused by skewed code usage, where a few popular codewords absorb most items) and a geometry penalty (caused by forcing curved embedding manifolds onto flat Euclidean grids, as RQ-VAE does). As a proof of concept, they introduce Decoupled Residual Quantization (DRQ), which splits the usual joint training into two stages: a continuous VAE first learns the geometry without discrete codebook constraints, then post-hoc hierarchical K-Means assigns the frozen vectors to codes. They find that from a 15-million-item industrial short-video dataset, no single method wins every time. RQP-VAE leads on symbolic robustness and codebook utilization, plain DRQ-VAE dominates reconstruction fidelity, and adding contrastive learning (DRQ-VAE+CL) wins on soft behavior-aware matching. Their takeaway is that Semantic ID quality is genuinely multi-objective, so you should pick a tokenizer based on which axis your downstream task actually stresses.
📚 https://arxiv.org/abs/2606.01844
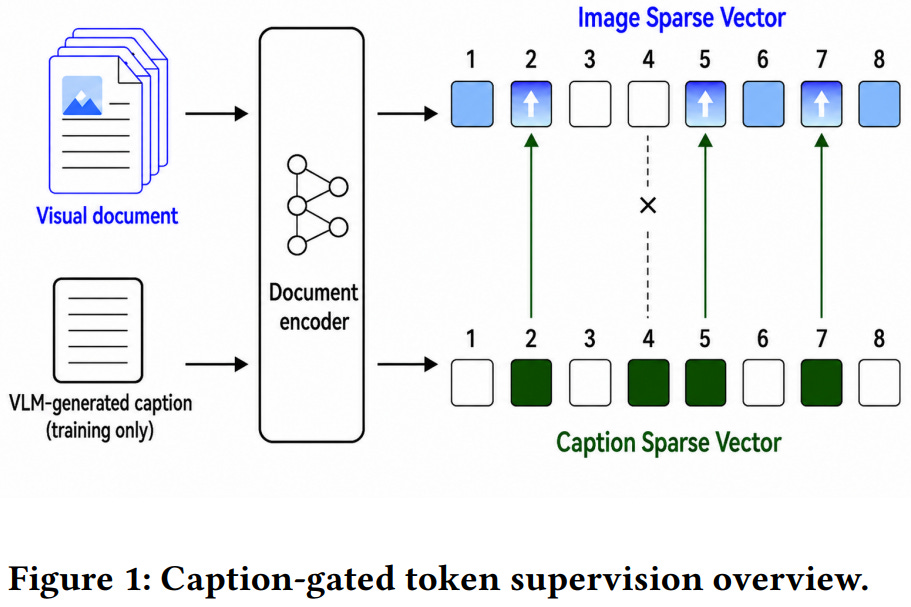
[4] Inference-Free Multimodal Learned Sparse Retrieval for Production-Scale Visual Document Search
This paper from Naver goes after a deployment gap in visual-document retrieval. Every existing approach either needs a neural encoder running on the query at serving time (dense and ColBERT-style multi-vector VLM retrievers) or needs each document converted to text upfront through slow OCR or caption generation (BM25 pipelines). What’s missing is a retriever that indexes page images directly and answers text queries with no neural encoding. The authors fill that gap with V-SPLADE, an inference-free multimodal learned sparse retriever built on a compact 250M-parameter vision-language backbone with an LM head. The core challenge they identify is “lexical grounding”, i.e., when a document’s words appear only as pixels rather than input tokens, the sparse encoder struggles to activate the right vocabulary dimensions. Their fix is caption-gated token supervision, a training-only signal that uses VLM-generated captions to reinforce the image-side vocabulary dimensions both views agree on, then drops the caption branch entirely at inference. Across six benchmarks, V-SPLADE beats the same-backbone dense model (BiModernVBERT) by +13.8pp average NDCG@5 and edges out OCR/caption BM25, while running at far lower query-time FLOPs. On an 18.7M-page corpus it more than doubles the dense baseline’s R@5, encodes documents 20x faster than OCR or caption pipelines, holds recall better as the corpus grows, and serves queries in the sub-millisecond range with two-stage search. It’s also complementary rather than a replacement, lifting both dense retrievers and multi-vector rerankers through score fusion.
📚 https://arxiv.org/abs/2605.30917
👨🏽💻 https://github.com/naver/v-splade
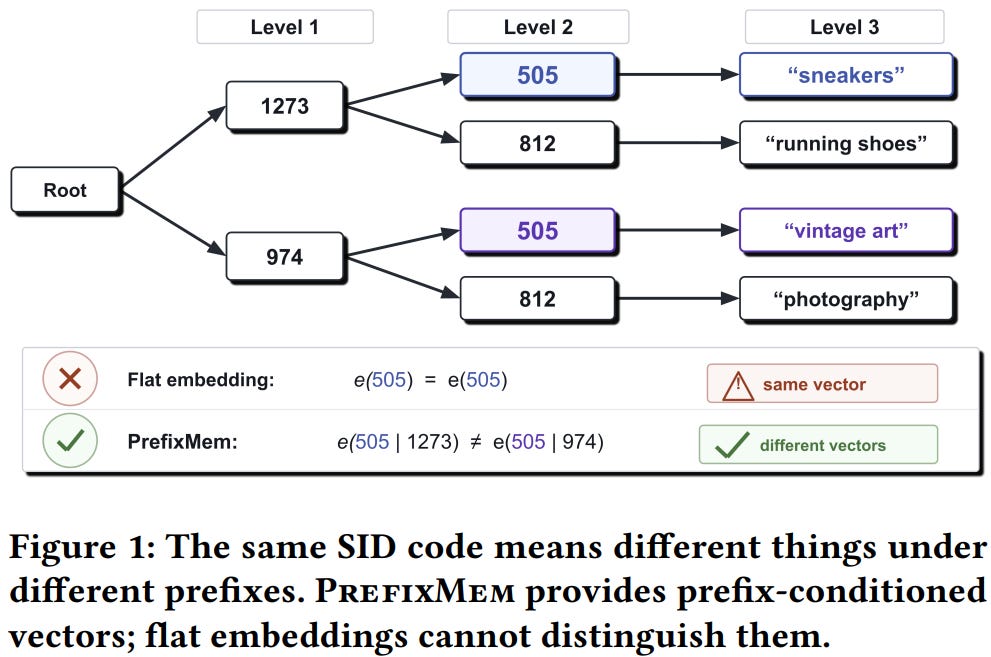
[5] LLMs Need Encoders for Semantic IDs Too
This paper from Pinterest argues that Semantic IDs (SIDs) should be treated like a separate modality requiring a dedicated encoder, much as multimodal LLMs use vision or audio encoders. The core problem is that a SID code’s meaning depends on its prefix context (code 505 means “sneakers” after one prefix and “vintage art” after another), but standard systems just dump SID tokens into the vocabulary and force the model to learn these context-dependent meanings from scratch, which gets combinatorially expensive and sparse at deeper levels. Their solution, PrefixMem, is a lightweight encoder built on hash-based prefix n-gram memory tables. Before each SID token enters the transformer, it hashes the preceding codes into a prefix-conditioned vector and adds it to the token embedding, so the LLM sees a different representation for the same code depending on what came before. The encoder is cheap (sparse lookups, under 0.02% compute overhead), can be pre-trained independently, and transfers across model families. Testing on Pinterest data across Qwen, Llama, and Gemma, they show deepest-level SID accuracy improves up to 46% relative and full-SID recall up to 22%, with gains concentrating heavily on hard “unreachable” examples (+77%) and rare tail items (+115%).
📚 https://arxiv.org/abs/2606.00324
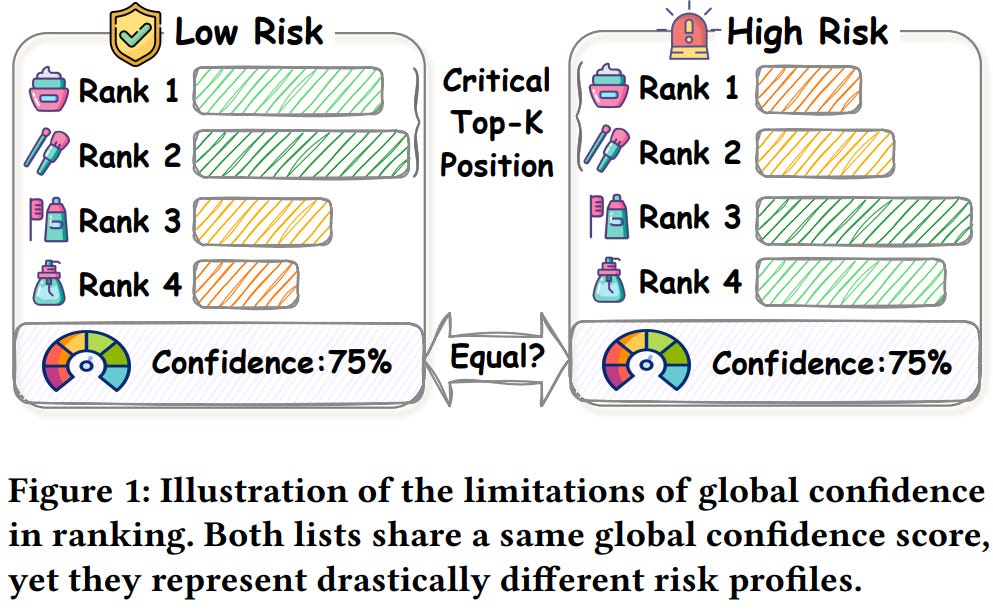
[6] EviRank: Evidence-Based Confidence Estimation for LLM-Based Ranking
This paper from Xidian University introduces Evidence-based Confidence Estimation for LLM-based Ranking (EviRank). When using LLMs as recommendation rankers, existing uncertainty methods either give one global confidence score that hides which positions in a ranked list are actually risky, or they produce position-level scores that come out uniformly low and flat. The authors fix this by pulling three kinds of evidence from a single forward pass of the model. Semantic evidence looks at the gap between consecutive items’ similarity to the user’s preference context, attention evidence measures how concentrated the attention distribution is via normalized entropy, and output evidence tracks the difference in max generation probability between neighboring positions. They convert each into belief masses using subjective logic, then fuse them with a reliable opinion aggregation rule that down-weights sources carrying high uncertainty. Since top ranks matter more than tail ones, they add a position-aware calibration that uses the NDCG discount factor and trains the confidence to match that target rather than treating it as a classification-style correctness probability. The calibrated confidence then feeds a reranking step optimized with BPR. Across MovieLens-1M, Amazon Grocery, and Steam, on Mistral, Llama3, and Qwen2.5 backbones, EviRank beats baselines including the prior state-of-the-art LLM4Rerank on both recommendation metrics (Recall, NDCG) and uncertainty metrics (Kendall’s tau, concordance index), with the biggest gains at top positions, and it runs faster than LLM4Rerank because everything rides on that single pass.
📚 https://arxiv.org/abs/2606.04727
👨🏽💻 https://anonymous.4open.science/r/EviRank-CDE0
[7] UniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale
This paper from Pinterest introduces UniPinRec to address a wasteful pattern in industrial recommenders where retrieval and ranking both run large transformers over the same user behavior data, yet they’re trained and served as separate models, duplicating parameters, compute, and serving cost. The authors aim for full-stack unification with one input format, one model, one training stage, deployed inside the existing serving stack. A shared transformer encodes the user action sequence once into candidate-independent representations, then branches into retrieval (ANN dot-product) and ranking (cross-attention) through task-specific heads. Masked Action Modeling concatenates action embeddings onto each item and randomly masks them during training, so ranking supervision rides on the same non-interleaved sequence retrieval already uses. Blended training examples pair a past action sequence with a future feedview impression slate (including negatives), letting a single joint loss satisfy both objectives. And cross-stage KV-cache sharing lets ranking reuse retrieval’s history encoding through a GPU memory pool mapped across processes, dropping ranking cost from O(n²) to O(nk). Offline, it lifts ranking Hit@3 by about 14.8% over the production ranker while matching retrieval recall, and joint training beats both a fine-tuned retrieval model and a ranking-only variant. In production A/B tests it delivers roughly +1% engagement while cutting end-to-end latency 11.1% and lifting QPS 63.6%, with stacked serving optimizations (KV reuse, flex attention, FP8) reaching nearly 4x ranking speedup.
📚 https://arxiv.org/abs/2606.00422
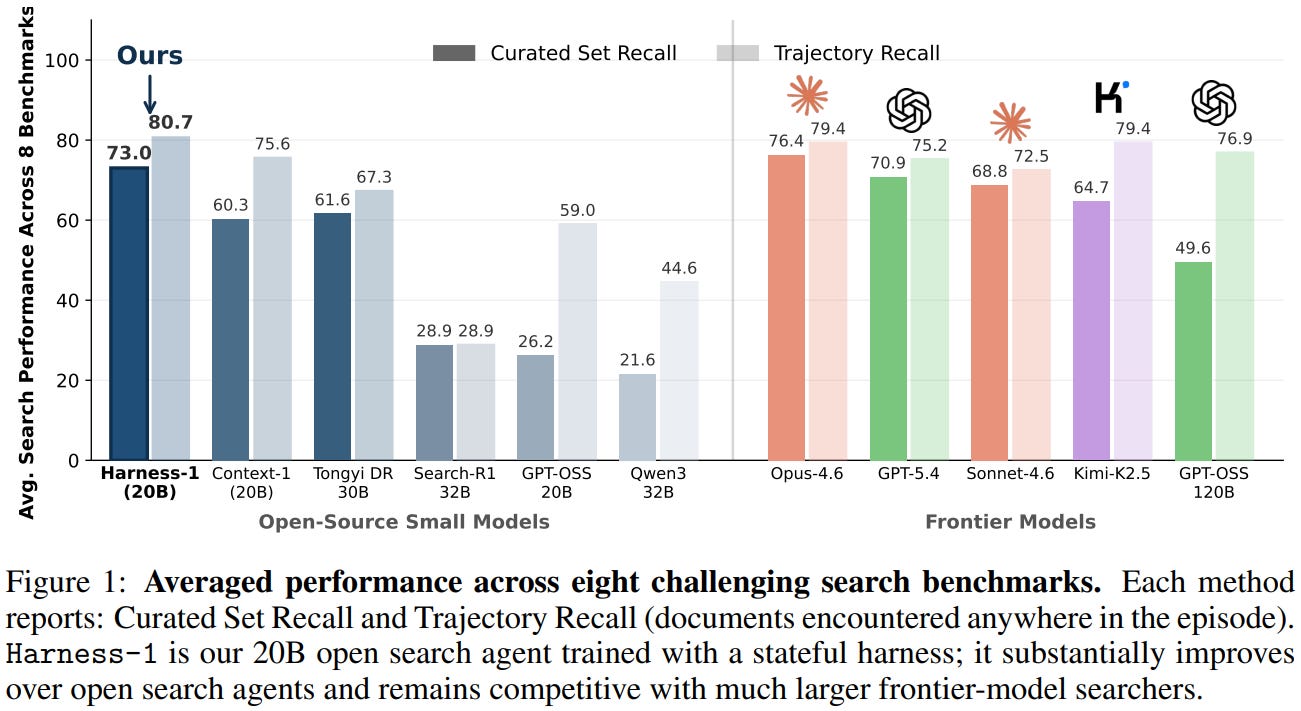
[8] Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
This paper from Jiang et al. introduces Harness-1, a 20B search agent that rethinks how retrieval agents get trained. The usual approach makes the model do everything at once: decide what to search for while also tracking what it has seen, which evidence matters, and what still needs checking. The authors argue this forces reinforcement learning to optimize routine bookkeeping the environment could handle more reliably. Their fix is “stateful cognitive offloading”. The policy keeps the semantic calls (what to search, which documents to keep, what to verify, when to stop) while a stateful harness maintains everything else: a candidate pool, an importance-tagged curated set capped at 30 documents, an evidence graph linking entities to documents, verification records, and compressed, deduplicated observations rendered within a context budget. The model acts by editing this working memory rather than just extending a transcript. Training runs in two stages: SFT on roughly 900 GPT-5.4 teacher trajectories to learn the interface, then CISPO reinforcement learning on SEC queries with a terminal reward that separates discovery from selection and includes a tool-diversity bonus, which the authors show is essential since the policy otherwise collapses into a shallow search-only loop. Across eight benchmarks spanning web, finance, patents, and multi-hop QA, Harness-1 hits 0.730 average curated recall, beating the next open agent by 11.4 points and topping every frontier searcher except Opus-4.6, all on a fraction of the training data.
📚 https://arxiv.org/abs/2606.02373
👨🏽💻 https://github.com/pat-jj/harness-1
[9] Do Neural Retrievers Prefer Certain Documents? Evidence of Learned Relevance Priors
This paper from Valentini et al. asks whether neural retrievers learn to prefer certain documents independent of the query, picking up biases baked into how IR datasets get annotated. Annotators only label a subset of documents as relevant, and that subset tends to favor certain topics, styles, and formats. The authors call the result a “relevance prior,” a query-independent signal P(R|d) that bi-encoders absorb during training as a side effect rather than by design. To measure it, they train a simple logistic regression classifier on frozen document embeddings to separate judged-relevant documents from unjudged ones, then check whether that signal generalizes to held-out documents and other datasets. A toy experiment confirms the mechanism: inject a spurious token into most relevant training documents, and the fine-tuned model carves positive and unjudged documents into distinct embedding regions, while BM25 and the base model show no such split. Scaling up to three strong MTEB retrievers (BGE, NV-Embed, GTE) across ten-plus benchmarks, they find the prior generalizes to unseen documents, stays consistent across models, and produces a “findability gap” where low-prior documents rank worse even when genuinely relevant. The effect holds for supervised dense retrievers but is weak and inconsistent in BM25, and survives a matched-pair experiment that controls for confounders like document length and graded relevance, which points to the prior itself driving the gap rather than surface features. Finally, they use an LLM-based explain-then-classify method to characterize what these documents look like: annotation favors comprehensive, self-contained summaries of mainstream topics, while niche, fragmentary, or technical content gets left unjudged, and retrievers internalize exactly that preference, rewarding the “macro” (encyclopedic, structured, explanatory) over the “micro” (practical how-to guides, raw data, technical fragments).
📚 https://arxiv.org/abs/2606.02814
[10] When Knowledge Is Not Free: Cost-Aware Evidence Selection in Retrieval-Augmented Generation
This paper from Wu et al. tackles a gap in how we evaluate RAG. Most work assumes external knowledge is free, but real high-quality sources are often paywalled, licensed, or otherwise costly to reach. The authors introduce cost-aware RAG, where each piece of retrieved evidence carries an access-cost tier and the system must answer within an explicit budget. They build a testbed by augmenting MS MARCO v2.1 with three discrete cost tiers (free, low-cost, costly), using an LLM to classify the highest-coverage domains and imputing the long tail. They then evaluate on open-domain benchmarks (HotpotQA, NQ, TriviaQA) and medical ones (MedQA-US, MMLU-Med), where the costly tier gets seeded with domain-matched textbook evidence. Their first finding is that static evidence-selection rules are brittle: across five selectors (relevance-only, greedy cost-normalized, knapsack, redundancy-aware knapsack, and MMR with a cost penalty), no method consistently wins across datasets, budgets, or backbones, and larger budgets rarely improve answers since the fixed evidence window means a bigger budget mostly swaps cheap passages for expensive ones rather than adding context. This motivates an agentic formulation, where a ReAct-style LLM decides when to retrieve, which tier to pull from, and when to stop. The results are mixed. Qwen3-8B often matches or beats fixed selectors while spending far less and using only a couple of passages, but Llama-3.1-8B-Instruct tends to burn through its budget without payoff. The core takeaway is that knowing when added evidence is worth its access cost is an under-explored RAG capability, and current LLMs are still unreliable, cost-sensitive controllers.
📚 https://arxiv.org/abs/2606.02245
👨🏽💻 https://github.com/Mignonmy/Cost-Aware

I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.