
Agentic Retrieval for Corpus-Level Reasoning, Compact, High-Performance Caching for RAG Agents, and More!
Vol.129 for Nov 03 - Nov 09, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Reinforcement Learning for Multi-Tool Retrieval-Augmented Generation, from Fudan University
A Multi-Agent Framework for Search-Augmented Multi-Perspective Knowledge Integration, from Virginia Tech
Improving Retrieval for Multi-Answer Queries via Multi-Vector Embeddings, from NYU
Accelerating RAG Through Accuracy-Preserving Context Reuse and Intelligent Document Ordering, from the University of Edinburgh
Compact, High-Performance Caching for RAG Agents, from Lin et al.
Stabilizing Context Length in Multi-Turn Search Agents Through Dynamic Memory Updates, from Yuan et al.
End-to-End Optimization of Retrieval-Augmented Generation Pipelines via Evolutionary Methods, from Kartal et al.
A Taxonomy-Based Hard-Negative Sampling Strategy for Personalized Semantic Search, from The Home Depot
Identifying and Eliminating LLM-Corpus Knowledge Overlap in Retrieval-Augmented Generation, from Fudan University
Strategic Task Allocation Between Traditional RecSys and LLMs for Improved User Coverage, from the University of Washington
[1] MARAG-R1: Beyond Single Retriever via Reinforcement-Learned Multi-Tool Agentic Retrieval
This paper from Fudan University addresses the inherent limitations of standard RAG systems, which typically rely on a single retriever with a fixed top-k selection, thereby creating a bottleneck for tasks that require corpus-level reasoning. The authors propose MARAG-R1, a framework that reframes RAG as a multi-tool agentic retrieval problem. This model equips an LLM agent with four specialized tools: semantic search, keyword search, filtering, and aggregation. Training follows a two-stage process, beginning with supervised fine-tuning (SFT) on expert-generated trajectories to establish baseline tool usage. Subsequently, the agent is refined through reinforcement learning, optimizing a composite reward function that uniquely combines signals for final answer accuracy (token F1), document coverage (document F1), and strategic tool exploration. Experiments on the GlobalQA benchmark show that MARAG-R1 achieves new state-of-the-art results, significantly outperforming both graph-based and other agentic RAG baselines.
📚 https://arxiv.org/abs/2510.27569
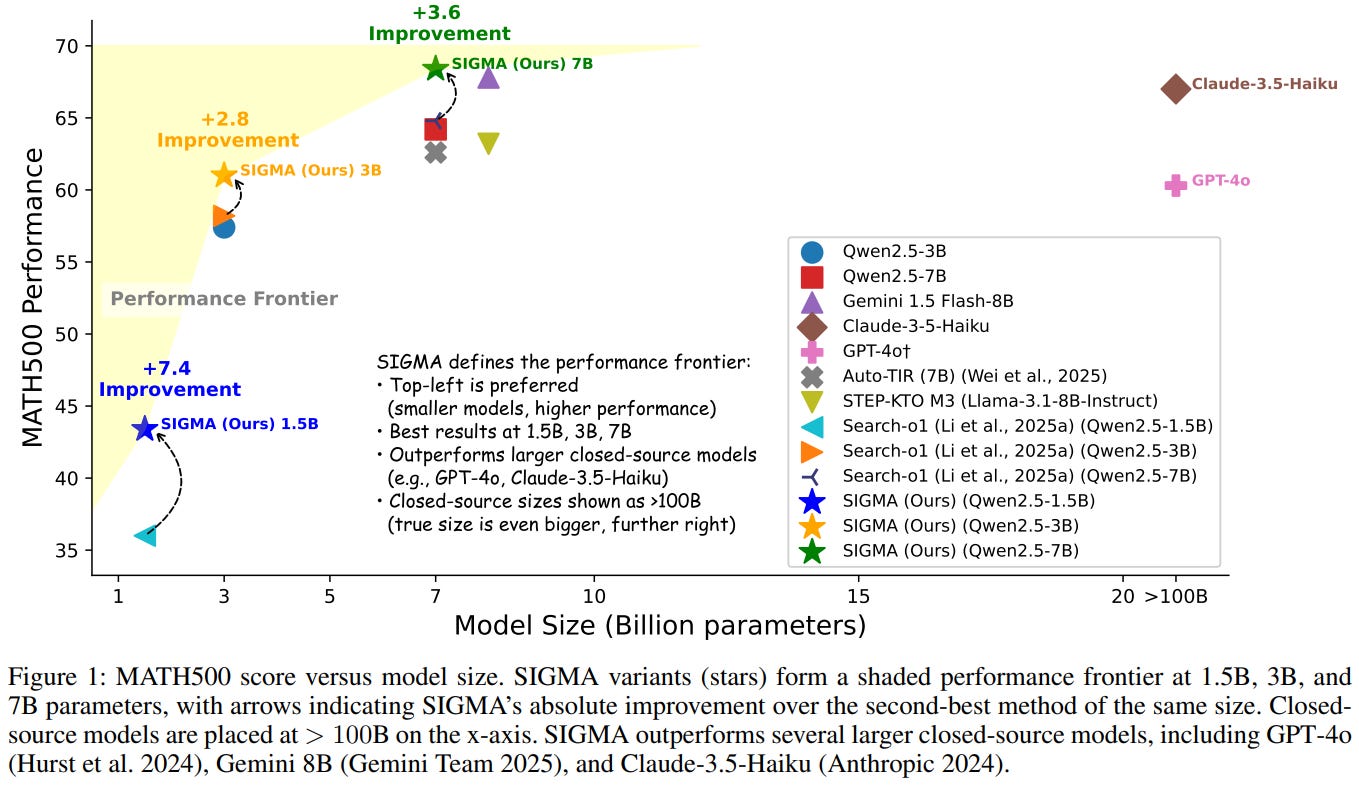
[2] SIGMA: Search-Augmented On-Demand Knowledge Integration for Agentic Mathematical Reasoning
This paper from Virginia Tech introduces SIGMA to address the limitations of current retrieval-augmented models in solving complex mathematical reasoning problems, where inflexible, single-perspective search strategies often fail to surface critical facts during multi-step analysis. SIGMA is a unified agentic framework that orchestrates four specialized agents (Factual, Logical, Computational, and Completeness) to perform multi-perspective, on-demand knowledge integration. These agents independently execute reasoning-search cycles, triggering retrieval only when uncertainty arises. To ensure queries are highly relevant to each agent’s analytical needs, the framework utilizes Hypothetical Document Enhancement (HyDE) for targeted retrieval. A lightweight, heuristic-based moderator then synthesizes the outputs, deduplicating findings and resolving conflicts via a pre-defined prioritization scheme.
📚 https://arxiv.org/abs/2510.27568
[3] Beyond Single Embeddings: Capturing Diverse Targets with Multi-Query Retrieval
This paper from NYU argues that the single-vector retrieval struggles when queries have multiple, distinct relevant documents, such as in cases of ambiguity or list-based answers. The authors first quantify this failure, demonstrating that the performance of existing retrievers degrades significantly as the embedding distance between target documents increases. To overcome this, they propose the Autoregressive Multi-Embedding Retriever (AMER), an architecture that autoregressively generates a sequence of query embeddings rather than a single vector. A key component of its training is the use of the Hungarian matching algorithm to dynamically and optimally pair the generated query vectors with the unordered set of target document embeddings before calculating the InfoNCE contrastive loss. At inference, each generated vector retrieves a separate ranked list, and these lists are aggregated using a round-robin approach.
📚 https://arxiv.org/abs/2511.02770
👨🏽💻 https://github.com/timchen0618/amer [not public as of 11/07]
[4] RAGBoost: Efficient Retrieval-Augmented Generation with Accuracy-Preserving Context Reuse
This paper from the University of Edinburgh introduces RAGBoost, a system designed to accelerate RAG by efficiently reusing cached contexts without sacrificing accuracy. The authors identify that existing caching approaches face a fundamental trade-off: exact prefix matching preserves accuracy but achieves low cache reuse (4-5% hit rates), while approximate KV-cache matching improves reuse at the cost of 9-11% accuracy degradation. RAGBoost addresses this through three key mechanisms: (1) a hierarchical context index that tracks cached contexts and enables fast lookup based on document overlap rather than exact token matches, (2) a context ordering algorithm that reorders retrieved documents to maximize prefix overlap across sessions while using concise “order hints” to preserve the original retrieval semantics, and (3) context de-duplication with “location hints” that eliminates redundant documents in multi-turn conversations by referencing their prior occurrences. Evaluated across multiple RAG workloads and LLMs, RAGBoost achieves 1.5-3x prefill throughput improvements over state-of-the-art systems.
📚 https://arxiv.org/abs/2511.03475
👨🏽💻 https://github.com/Edinburgh-AgenticAI/RAGBoost
[5] Cache Mechanism for Agent RAG Systems
This paper from Lin et al. introduces ARC (Agent RAG Cache Mechanism), a caching framework designed to address the storage and latency challenges faced by RAG-powered LLM agents operating with massive knowledge repositories. Unlike existing caching approaches that rely on exact prefix matching (yielding low cache hit rates) or approximate KV-cache matching (degrading accuracy), ARC operates at the document level by maintaining compact, semantically relevant caches tailored to each agent’s domain. The system combines two complementary scoring mechanisms: (1) a Distance-Rank Frequency (DRF) score that weights retrieved documents based on both their retrieval rank and embedding distance from queries, capturing dynamic query-driven demand, and (2) a hubness score that identifies semantically central documents by measuring how frequently they appear in other documents’ k-nearest-neighbor lists within the embedding space, representing query-agnostic structural importance. These scores are synthesized into a unified priority function that guides cache maintenance decisions while respecting capacity constraints. Evaluated on three QA datasets (SQuAD, MMLU, AdversarialQA) with a 6.4-million-document Wikipedia corpus, ARC achieves a 79.8% has-answer rate while reducing storage requirements to just 0.015% of the original corpus and cutting average retrieval latency by 80% compared to full-index search.
📚 https://arxiv.org/abs/2511.02919
[6] MemSearcher: Training LLMs to Reason, Search and Manage Memory via End-to-End Reinforcement Learning
This paper from Yuan et al. introduces MemSearcher, an agent workflow designed to address the significant efficiency and scalability limitations of ReAct-style search agents. Traditional agents that concatenate the entire interaction history suffer from quadratically scaling computational costs and performance degradation as the context grows. MemSearcher avoids this by tasking the LLM to iteratively maintain a single, compact memory state. At each interaction turn, the model receives only the user’s question and this compact memory, subsequently functioning as its own memory manager to update the state with only essential information after performing a search action. To optimize this complex workflow, the authors propose multi-context GRPO (Group Relative Policy Optimization), an end-to-end reinforcement learning framework. This method extends GRPO to jointly train the agent’s reasoning, search, and memory management capabilities by handling trajectories composed of multiple conversations under different memory contexts. When trained on the Search-R1 dataset, MemSearcher demonstrates superior efficiency by maintaining a stable context length, achieving relative average gains of +11% to +12% on seven public benchmarks and enabling a 3B model to outperform 7B baselines.
📚 https://arxiv.org/abs/2511.02805
👨🏽💻 https://github.com/icip-cas/MemSearcher [not public as of 11/07]
[7] RAGSmith: A Framework for Finding the Optimal Composition of Retrieval-Augmented Generation Methods Across Datasets
This paper from Kartal et al. presents RAGSmith, a framework designed to overcome the limitations of traditional, per-module optimization for RAG pipelines. The authors argue that optimizing components in isolation ignores complex inter-component synergies and domain-specific requirements. RAGSmith reframes RAG design as an end-to-end architecture search problem, defining a combinatorial space of 46,080 feasible configurations across nine distinct technique families, including pre-embedding, query expansion, reranking, and post-generation. A genetic search algorithm efficiently explores this space, optimizing a scalar objective that jointly aggregates retrieval metrics (like nDCG and MRR) and generation quality (measured by LLM-Judge and semantic similarity). Experiments across six Wikipedia-derived domains demonstrate that discovered configurations consistently outperform naive RAG baselines, improving average performance by +3.8%. Notably, passage compression techniques were never selected in the search, and performance gains were largest on factual and long-answer queries, suggesting current RAG optimizations are less effective for interpretation-heavy inferential tasks.
📚 https://arxiv.org/abs/2511.01386
👨🏽💻 https://github.com/yAquila/RAGSmith
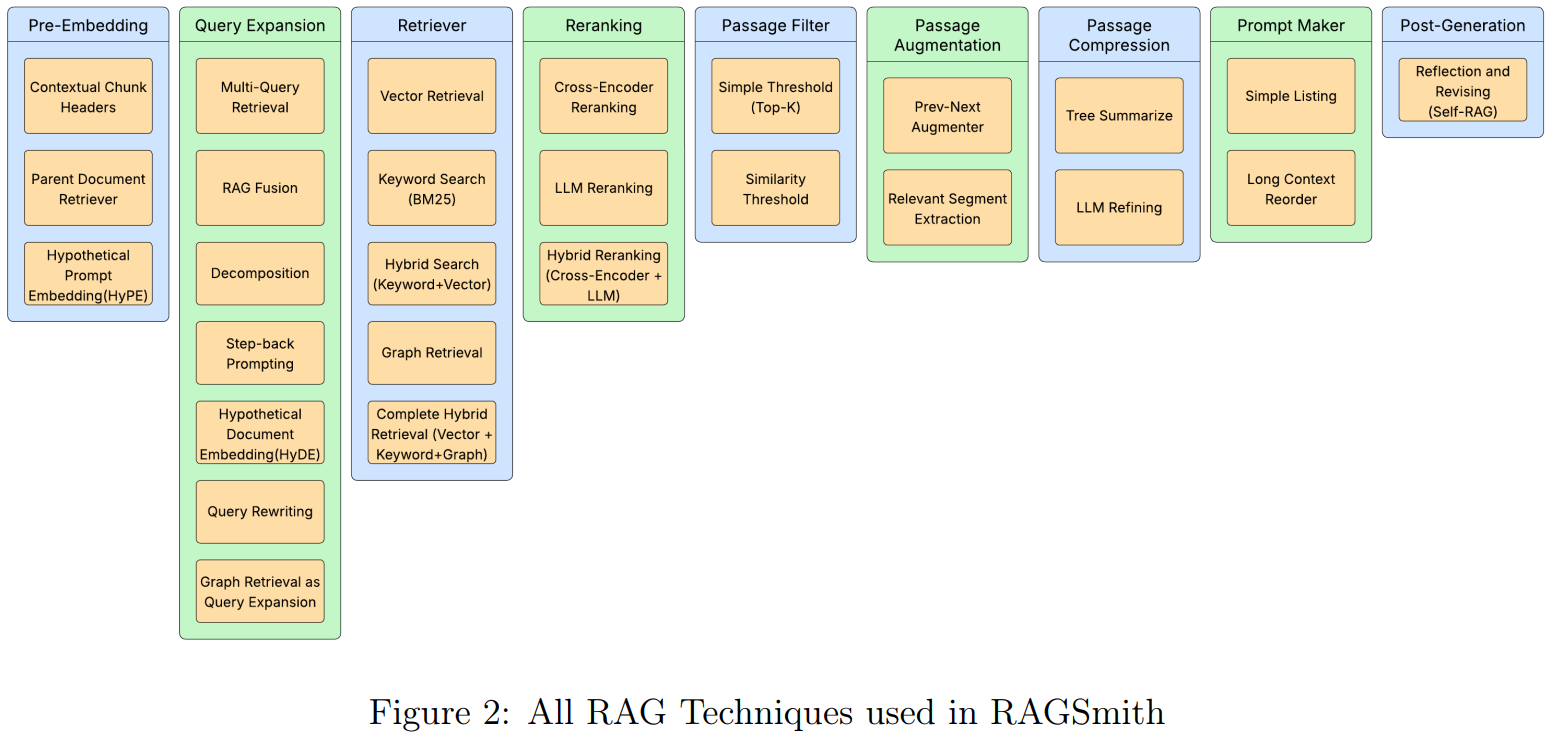
[8] Taxonomy-based Negative Sampling In Personalized Semantic Search for E-commerce
This paper from The Home Depot presents a personalized semantic search system for e-commerce that addresses the challenge of retrieving relevant products by combining query understanding with user behavior patterns. The authors introduce a taxonomy-based hard-negative sampling (TB-HNS) strategy that leverages product category hierarchies to generate contextually similar but distinct negative examples during training, enabling the model to learn fine-grained distinctions between related items (such as brand, size, or finish differences). The system employs a two-tower architecture with BERT-based encoders, enhanced with a personalization component that integrates customer purchase history and demographic features when beneficial, while falling back to non-personalized retrieval otherwise. Live A/B testing showed a meaningful business impact with 2.70% increase in conversion rate, 2.04% gain in add-to-cart rate, and 0.6% improvement in average order value.
📚 https://arxiv.org/abs/2511.00694
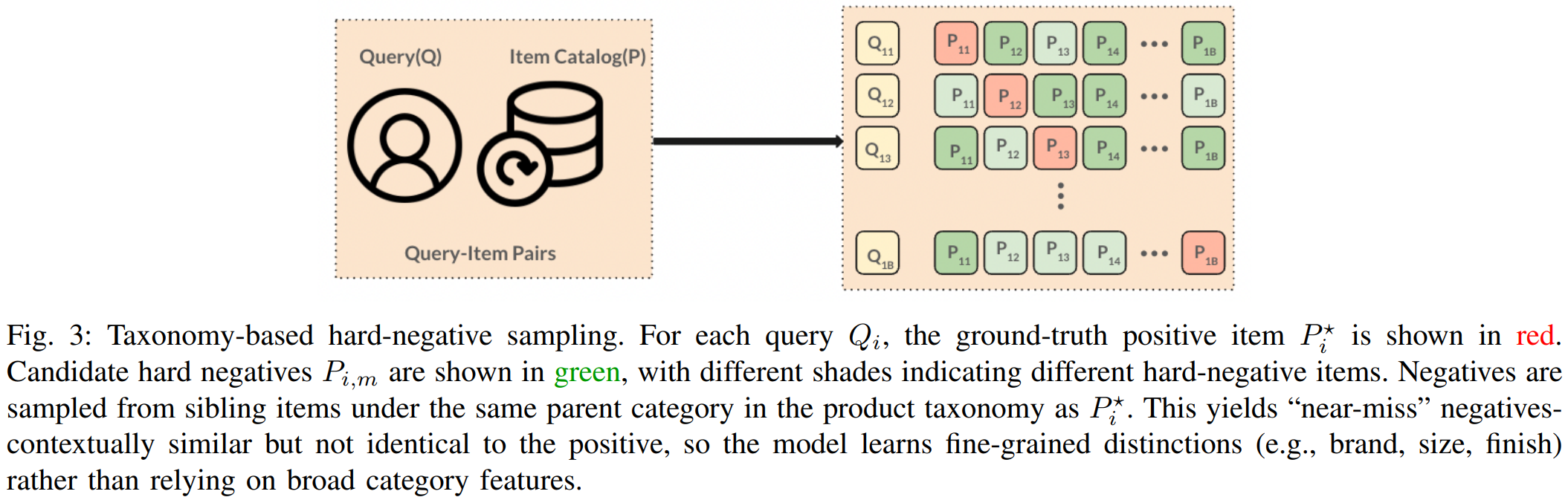
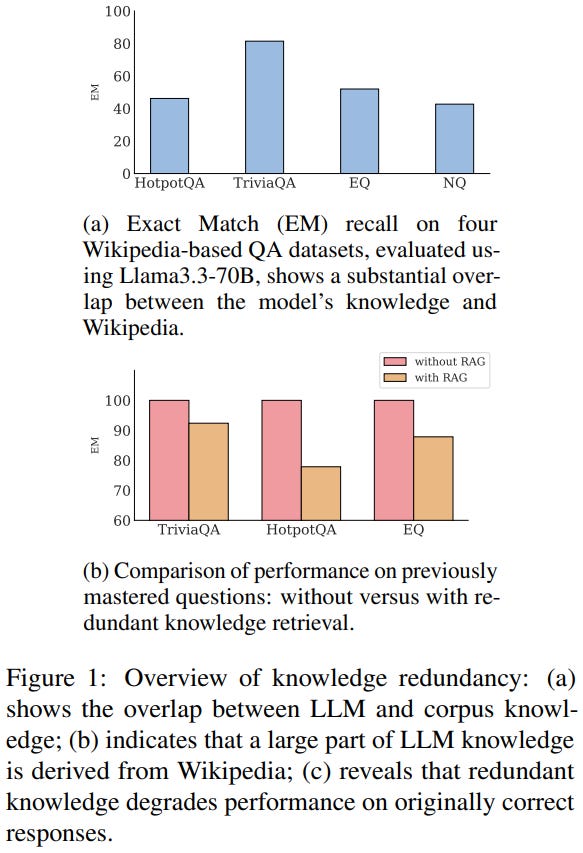
[9] Zero-RAG: Towards Retrieval-Augmented Generation with Zero Redundant Knowledge
This paper from Fudan University introduces Zero-RAG, a framework that addresses knowledge redundancy between LLMs and external retrieval corpora in RAG systems. The authors observe that modern LLMs have accumulated substantial internal knowledge that overlaps with standard retrieval corpora like Wikipedia (e.g., Llama3.3-70B achieves 40%+ accuracy on Wikipedia-based questions without retrieval), and that providing redundant knowledge through retrieval actually degrades performance on questions the LLM can already answer correctly (approximately 20-point drop). To tackle this, Zero-RAG proposes three key components: (1) a Mastery-Score metric that quantifies how well an LLM has mastered specific passages by generating question-answer pairs and measuring the model’s ability to answer them correctly, enabling intelligent corpus pruning; (2) a Query Router that determines whether a query requires external retrieval or can be answered using the LLM’s internal knowledge; and (3) Noise-Tolerant Tuning that trains the model to ignore irrelevant retrieved documents and rely on internal knowledge when appropriate. Experiments show this approach can prune 30% of the Wikipedia corpus and accelerate retrieval latency by 22%, all while maintaining RAG performance on key QA benchmarks.
📚 https://arxiv.org/abs/2511.00505
[10] Efficient and Responsible Adaptation of Large Language Models for Robust Top-k Recommendations
This paper from the University of Washington proposes a hybrid recommendation framework that strategically combines traditional recommendation systems with LLMs to improve robustness for underserved users while managing computational costs. The authors identify “weak users” as those with sparse interaction histories who receive poor recommendations from conventional RS. They use two criteria: an AUC score below 0.5 and sparsity above the dataset average. For these weak users, the framework contextualizes their interaction histories as natural language prompts and leverages LLMs’ zero-shot ranking capabilities through in-context learning, while strong users continue receiving RS-generated recommendations. Evaluated across three datasets with eight diverse recommendation algorithms (including collaborative filtering, sequential, and learning-to-rank models) and three LLMs (GPT-4, Claude 3.5, LLaMA 3-70B-Instruct), the framework demonstrates approximately 12% reduction in weak users while maintaining cost-effectiveness through targeted LLM utilization.
📚 https://dl.acm.org/doi/10.1145/3774778
👨🏽💻 https://github.com/i-kiran/TORS_LLMRecSys
Extras: Tools
🛠️ Trove: A Flexible Toolkit for Dense Retrieval
Trove is an open-source toolkit designed to simplify dense retrieval research by integrating data management, modeling, and evaluation within a single flexible framework. Trove provides efficient on-the-fly data loading and processing, reducing memory use without requiring large preprocessed datasets, and offers a modular structure that allows users to freely customize or replace components such as encoders, losses, and retrievers. It includes a unified interface for training, evaluation, and hard negative mining, supporting distributed multi-node and multi-GPU execution without code changes.
📝 https://arxiv.org/abs/2511.01857
👨🏽💻 https://github.com/BatsResearch/trove
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.