
Unifying Retrieval and Reranking with Embedding Models, Learning to Reason for Recommendations, and More!
Vol.128 for Oct 27 - Nov 02, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
A Unified Embedding Model for Efficient Retrieval and Listwise Reranking, from Alibaba
Activating Latent Reasoning Capabilities in LLMs for Reranking with Minimal Supervision, from Yale NLP Lab
Reinforcement Learning for Autonomous Reasoning in Recommender Systems, from Alibaba
An Open-Source Framework for Scaling Generative Recommendation Systems, from Kong et al.
A Framework for Autonomous Tool-Using Agents, from Xiaohongshu
Scaling Long Behavior Sequence Modeling Across Domains in Production Advertising Systems, from Tencent
A Unified Transformer Architecture for Joint Sequence Modeling and Feature Interaction in Recommendation Systems, from ByteDance
An Enterprise-Scale Embedding Model Unifying Five Modalities with Matryoshka Representations, from Amazon
A Utility-Based Metric for Evaluating Retrieval in RAG Systems, from Trappolini et al.
Bridging Efficiency and Accuracy in Visual Document Retrieval through Hybrid-Vector Methods, from Kim et al.
[1] E²Rank: Your Text Embedding can Also be an Effective and Efficient Listwise Reranker
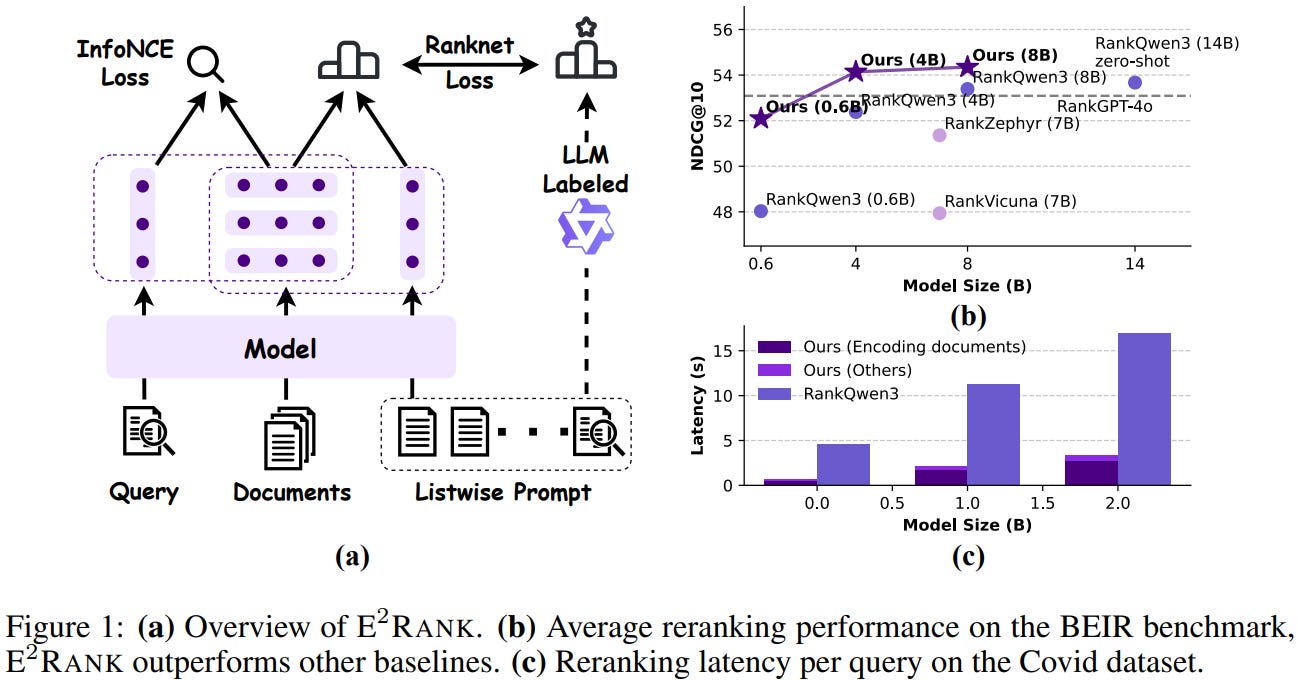
This paper from Alibaba introduces E²RANK, a unified framework that enables a single text embedding model to perform both efficient retrieval and high-quality listwise reranking. The key innovation involves reinterpreting the listwise prompt (containing query and candidate documents) as a pseudo-relevance feedback (PRF) query, allowing the model to use simple cosine similarity between embeddings as a unified ranking function instead of expensive autoregressive generation used by LLM-based rerankers like RankGPT. The training occurs in two stages: first, standard contrastive learning trains a base embedding model, then continued training with a multi-task objective combines InfoNCE loss (for embedding quality) and RankNet loss (for ranking capability). Experiments demonstrate that E²RANK achieves state-of-the-art performance on the BEIR reranking benchmark and competitive results on the reasoning-intensive BRIGHT benchmark, while being approximately 5x faster than comparable listwise rerankers at inference time.
📚 https://arxiv.org/abs/2510.22733
👨🏽💻 https://alibaba-nlp.github.io/E2Rank/
[2] LimRank: Less is More for Reasoning-Intensive Information Reranking
This paper from Yale NLP Lab introduces LIMRANK, a reranking model that demonstrates modern LLMs can be effectively adapted for information reranking tasks using minimal, high-quality supervision rather than large-scale fine-tuning. The authors design LIMRANK-SYNTHESIZER, an open-source pipeline for generating diverse, challenging, and realistic reranking examples guided by three core principles: domain diversity, alignment with real-world use cases, and difficulty diversity. The pipeline augments queries from MS MARCO by incorporating varied personas to generate both daily-life and expert-domain contexts, then creates positive and negative passages with corresponding reasoning chains generated by DeepSeek-R1. Using only 20K synthetic examples (less than 5% of data used in prior work like Rank1), LIMRANK fine-tunes Qwen2.5-7B and achieves state-of-the-art performance on reasoning-intensive retrieval (BRIGHT benchmark with 28.0% nDCG@10) and instruction-following retrieval (FOLLOWIR with 1.2 p-MRR score).
📚 https://arxiv.org/abs/2510.23544
👨🏽💻 https://github.com/SighingSnow/LimRank
[3] Think before Recommendation: Autonomous Reasoning-enhanced Recommender
This paper from Alibaba introduces RecZero, a reinforcement learning-based recommender system that addresses limitations of existing distillation-based approaches for rating prediction tasks. Traditional methods rely on teacher LLMs to generate reasoning traces that student models then mimic through supervised fine-tuning, but these approaches suffer from limited recommendation capability of general-purpose teachers, costly static supervision, and superficial transfer of reasoning abilities. RecZero employs a single LLM trained via pure RL using “Think-before-Recommendation” prompts that decompose reasoning into structured steps (analyzing user interests, item features, user-item compatibility, and rating prediction) with rule-based rewards computed through Group Relative Policy Optimization (GRPO). The authors also propose RecOne, a hybrid approach that combines cold-start supervised fine-tuning on high-quality reasoning trajectories with subsequent RL optimization. The RL paradigm proves more cost-effective than distillation methods, requiring 88% fewer labeled samples while achieving 21.5% better MAE than the strongest supervised baseline, and offers simpler deployment with a single-model, single-stage pipeline compared to multi-model distillation approaches.
📚 https://arxiv.org/abs/2510.23077
👨🏽💻 https://github.com/AkaliKong/RecZero
[4] MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation
This paper from Kong et al. presents MiniOneRec, the first fully open-source framework for generative recommendation systems that investigates whether scaling laws observed in LLMs transfer to recommendation tasks. Unlike conventional recommenders dominated by massive embedding tables that plateau with scale, MiniOneRec employs a generative paradigm that converts items into compact Semantic ID (SID) sequences via Residual Quantized VAE and trains autoregressive Transformers (Qwen backbones from 0.5B to 7B parameters). The framework validates consistent scaling laws, with both training and evaluation losses decreasing as model size increases, and introduces a lightweight post-training pipeline comprising two key innovations: (1) full-process SID alignment that bridges natural language understanding with SID tokens throughout both supervised fine-tuning (SFT) and reinforcement learning (RL) stages, and (2) reinforced preference optimization using Group Relative Policy Optimization (GRPO) with constrained beam search decoding and hybrid rewards combining rule-based accuracy with ranking-aware penalties for hard negatives. Experiments demonstrate that MiniOneRec significantly outperforms traditional collaborative filtering, review-based, and existing LLM-based recommenders, while comprehensive ablations reveal that pre-trained LLM weights, continuous alignment objectives, and beam search with hybrid rewards are critical for performance, with the framework also exhibiting promising cross-domain transferability despite never seeing target domains during training.
📚 https://arxiv.org/abs/2510.24431
👨🏽💻 https://github.com/AkaliKong/MiniOneRec
🤗 https://huggingface.co/kkknight/MiniOneRec
[5] DeepAgent: A General Reasoning Agent with Scalable Toolsets
This paper from Xiaohongshu presents DeepAgent, an autonomous reasoning agent that integrates thinking, tool discovery, and action execution within a unified reasoning process. The system introduces an autonomous memory folding mechanism that compresses interaction history into structured episodic, working, and tool memories, enabling the agent to “take a breath” and reconsider strategies during long-horizon tasks while preventing context length explosion. To train the agent, the authors developed ToolPO (Tool Policy Optimization), an end-to-end reinforcement learning method that uses LLM-simulated APIs for stable training and employs fine-grained advantage attribution to assign credit specifically to tool invocation tokens, improving both final task success and intermediate action accuracy.
📚 https://arxiv.org/abs/2510.21618
👨🏽💻 https://github.com/RUC-NLPIR/DeepAgent
[6] Practice on Long Behavior Sequence Modeling in Tencent Advertising
This paper from Tencent presents their industrial practices for long-sequence user behavior modeling in online advertising, addressing the challenge of sparse ad interactions. The authors construct unified commercial behavior trajectories that integrate user behaviors across multiple advertising scenarios (WeChat Moments, Channels, Official Accounts) and extend into content domains, resulting in sequences with tens of thousands of items spanning months to years. They identify three core challenges: inter-field interference from heterogeneous feature taxonomies across domains, target-wise interference in temporal and semantic patterns when optimizing for different advertising objectives, and the need to model high-order correlations among numerous feature fields. Their solution employs a two-stage framework comprising (1) a search stage with hierarchical hard search for handling complex feature hierarchies and decoupled embedding-based soft search (DARE) to resolve conflicts between attention mechanisms and feature representation, and (2) a sequence modeling stage featuring Decoupled Side Information Temporal Interest Networks (DSI-TIN) to mitigate inter-field conflicts, Target-Decoupled Positional Encoding and Target-Decoupled SASRec for matching to address target-wise interference, and Stacked TIN to capture high-order behavioral correlations through multiple layers of target-attention. The system also introduces Standard Product Units (SPUs) to unify item representations across domains and implements extensive platform optimizations including parameter prefetch strategies, GPU acceleration techniques, and heterogeneous computation engines.
📚 https://arxiv.org/abs/2510.21714
[7] OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender
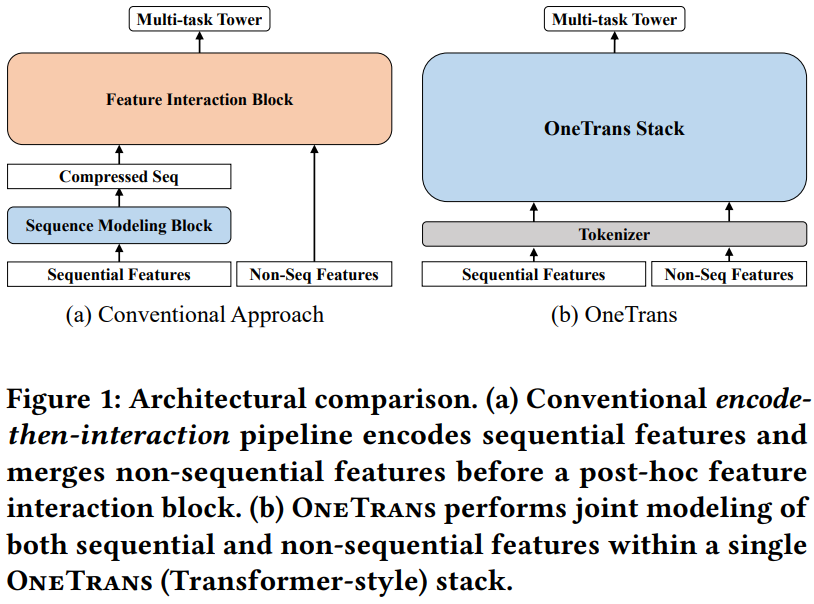
This paper from ByteDance introduces OneTrans, a unified Transformer architecture for industrial recommendation systems that simultaneously performs user behavior sequence modeling and feature interaction within a single backbone. The model employs a unified tokenizer converting both sequential (user behavioral sequences) and non-sequential features (user/item profiles, context) into a single token sequence, processed by stacked OneTrans blocks using mixed parameterization. Key efficiency innovations include a pyramid stacking strategy that progressively prunes sequential tokens across layers, cross-request KV caching that reuses user-side computations across candidates (reducing complexity from O(C) to O(1) for C candidates), and integration of LLM optimizations like FlashAttention-2 and mixed-precision training. Evaluated on a large-scale industrial dataset with 29.1B impressions, OneTrans demonstrates near log-linear scaling laws with increasing model parameters, outperforms strong baselines including RankMixer+Transformer, and achieves +5.68% lift in per-user GMV in online A/B tests while maintaining production-grade latency.
📚 https://arxiv.org/abs/2510.26104
[8] Amazon Nova Multimodal Embeddings: Technical report and model card
This paper from Amazon presents Nova Multimodal Embeddings (MME), an enterprise-grade embedding model capable of processing five distinct modalities (text, images, documents, video, and audio) within a unified semantic space, enabling comprehensive cross-modal retrieval and search applications. Nova MME employs a training paradigm combining next-token prediction and contrastive loss functions, while incorporating Matryoshka Representation Learning to support multiple embedding dimensions (3072, 1024, 384, and 256), allowing customers to balance precision against storage and latency requirements. Comprehensive benchmarking across standard datasets demonstrates that Nova MME achieves state-of-the-art performance on text-to-text retrieval (MMTEB benchmark with 116 languages), text-to-image (MSCOCO, TextCaps), text-to-document (ViDoRe v2), text-to-video (ActivityNet, DiDeMo), and text-to-audio (AudioCaps) tasks.
[9] Redefining Retrieval Evaluation in the Era of LLMs
This paper from Trappolini et al. addresses the misalignment between traditional Information Retrieval (IR) metrics and RAG systems where LLMs consume search results. The authors identify two critical limitations: (1) traditional metrics assume humans examine documents sequentially with diminishing attention to lower ranks, whereas LLMs process all retrieved documents holistically and exhibit complex positional biases rather than monotonic position-based preferences, and (2) classical metrics treat all irrelevant documents equally, failing to capture that some irrelevant passages actively distract LLMs and degrade generation quality while others have minimal impact. To address these issues, the authors propose a utility-based annotation schema that quantifies both the positive contribution of relevant passages and the negative distracting effects of irrelevant ones, replacing binary relevance judgments with continuous utility scores based on LLM abstention probabilities. Building on this framework, they introduce UDCG (Utility and Distraction-aware Cumulative Gain), a metric that combines average passage relevance with average distracting effect using an LLM-oriented positional discount optimized for correlation with end-to-end answer accuracy. Experiments across five datasets and six LLMs demonstrate that UDCG improves correlation with RAG performance and provides practitioners with a more reliable indicator of retrieval component quality that actually predicts downstream system effectiveness.
📚 https://arxiv.org/abs/2510.21440
👨🏽💻 https://github.com/GiovanniTRA/UDCG
[10] Hybrid-Vector Retrieval for Visually Rich Documents: Combining Single-Vector Efficiency and Multi-Vector Accuracy
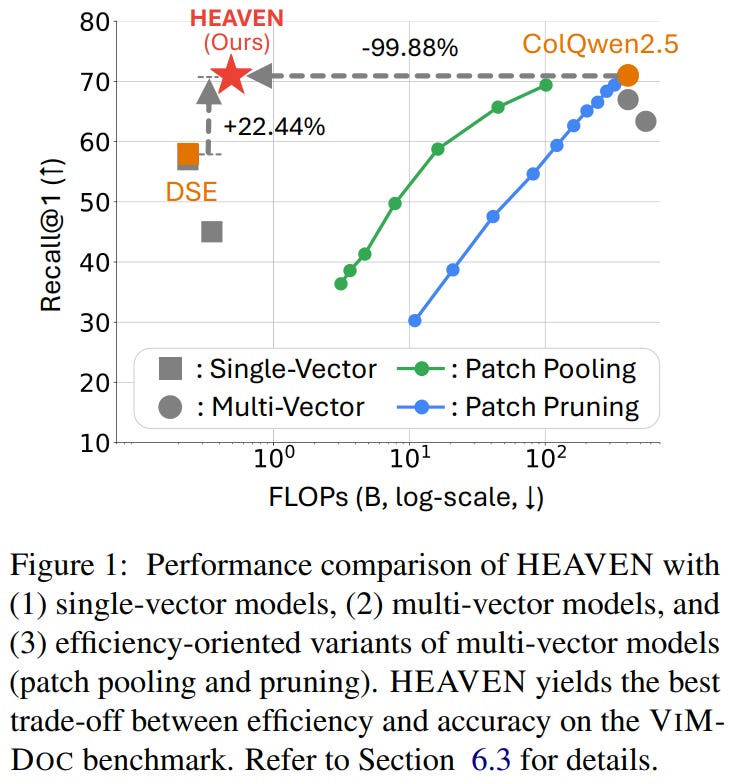
This paper from Kim et al. addresses the efficiency-accuracy trade-off in visual document retrieval by proposing HEAVEN (Hybrid-vector retrieval for Efficient and Accurate Visual multi-documENt), a two-stage framework that combines single-vector and multi-vector retrieval paradigms. The authors identify that single-vector methods are computationally efficient but less accurate, while multi-vector methods achieve higher accuracy at substantially greater computational cost. HEAVEN’s first stage efficiently retrieves candidate pages using single-vector retrieval over novel Visually-Summarized Pages (VS-Pages), which aggregate representative visual layouts from multiple pages to reduce redundant computation. The second stage reranks these candidates with a multi-vector method while filtering query tokens based on linguistic importance (such as nouns and named entities, comprising approximately 30% of tokens) to minimize unnecessary computations. To evaluate systems under realistic conditions, the authors introduce VIMDOC, a benchmark specifically designed for visually rich, multi-document, and long-document retrieval scenarios. Experiments across four benchmarks and six LLMs demonstrate that HEAVEN achieves 99.87% of the Recall@1 performance of the state-of-the-art multi-vector model ColQwen2.5 while reducing per-query computation by 99.82%, effectively bridging the gap between efficiency and accuracy in visual document retrieval systems.
📚 https://arxiv.org/abs/2510.22215
👨🏽💻 https://github.com/juyeonnn/HEAVEN [not public as of 10/31]
Extras: Benchmarks
⏱️ Towards Global Retrieval Augmented Generation: A Benchmark for Corpus-Level Reasoning
GlobalQA is a benchmark designed to evaluate RAG systems on corpus-level reasoning tasks that require integrating information across many documents rather than retrieving isolated text chunks. Built from over 13,000 question–answer pairs grounded in a corpus of 2,000 real-world resumes, GlobalQA includes four task categories: counting, extremum queries, sorting, and top-k extraction, each requiring aggregation and analysis across 2–50 documents.
📝 https://arxiv.org/abs/2510.26205
🤗 https://huggingface.co/datasets/QiiLuoo/GlobalQA
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.