
Scalable Update Strategies for Production LLM Recommendation Systems, Cost-Aware Retrieval-Augmented Reasoning, and More!
Vol.127 for Oct 20 - Oct 26, 2025

Stay Ahead of the Curve with the Latest Advancements and Discoveries in Information Retrieval.
This week’s newsletter highlights the following research:
Cost-Efficient Retrieval-Augmented Generation through Reinforcement Learning and Adaptive Retrieval, from Microsoft
A Comprehensive Survey of RL-Driven Agentic Search Systems, from Lin et al.
Semantic Alignment of Collaborative Filtering Embeddings with Language Models, from Wang et al.
Cost-Effective Adaptation of LLM Recommendation Systems Through Hybrid Fine-tuning and RAG, from Google
Enhancing Lightweight Dense Retrievers with Single-Layer Mixture-of-Experts, from the University of Milano-Bicocca
A Survey of Multimodal RAG Approaches for Visually Rich Document Understanding, from Gao et al.
Learning to Transform Retrieved Knowledge into Structured Representations for Enhanced LLM Reasoning, from Wu et al.
A Modular Framework for Transparent, Steerable, and Scalable Enterprise Deep Research, from Salesforce AI Research
Self-Reflective Reinforcement Learning for Tool-Augmented Question Answering, from Tsinghua University
A Systematic Comparison of Prompting and Reinforcement Learning for Query Augmentation, from Xu et al.
[1] Cost-Aware Retrieval-Augmentation Reasoning Models with Adaptive Retrieval Depth
This paper from Microsoft introduces Dynamic Search-R1, a retrieval-augmented reasoning model that enables language models to adaptively control retrieval depth by dynamically requesting additional documents from search results when needed. The authors address the computational inefficiency of existing retrieval-augmented reasoning systems by implementing cost-aware advantage functions for both Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) algorithms. They propose two cost penalization approaches: a memory-bound method that minimizes total token count, and a latency-bound method that distinguishes between generated tokens and retrieved tokens during encoding. Evaluated across seven question-answering datasets, their approach demonstrates substantial improvements over the Search-R1 baseline. Experiments with both 3B and 7B parameter Qwen models confirm that the cost-aware optimization successfully prevents unnecessary document retrieval requests and reduces reasoning chain verbosity without sacrificing answer quality.
📚 https://arxiv.org/abs/2510.15719
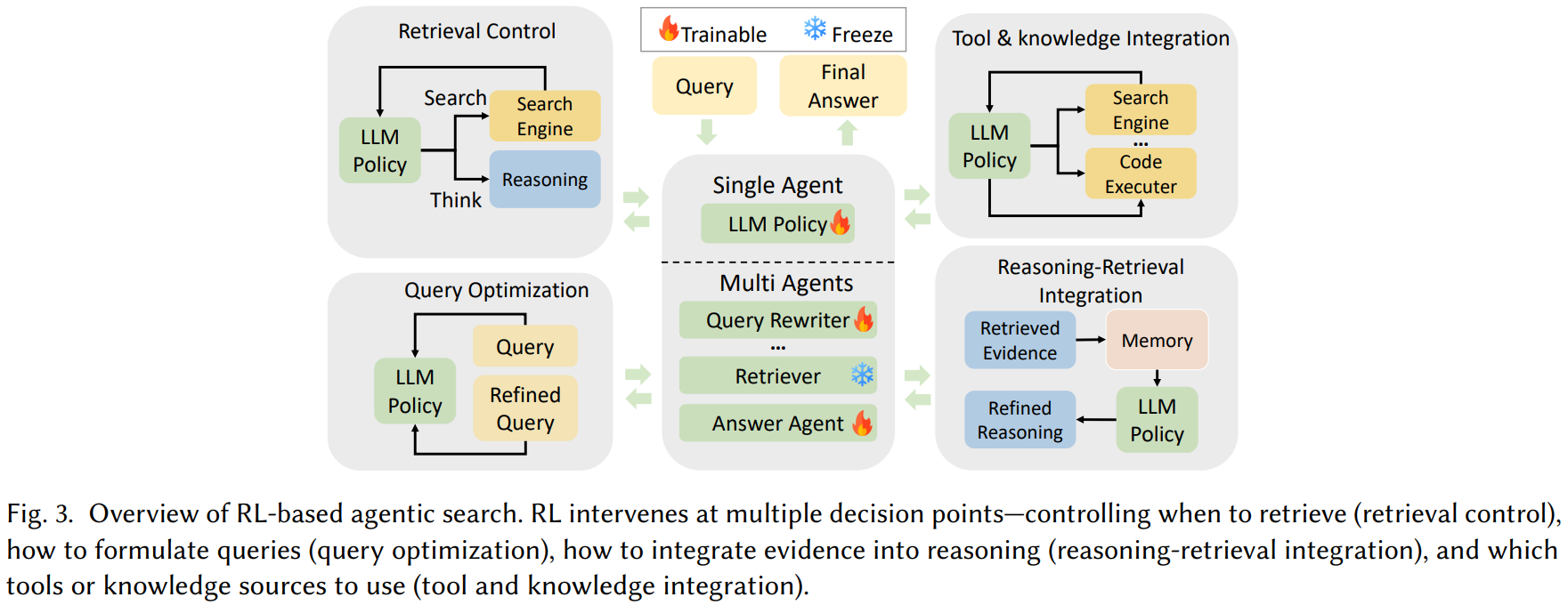
[2] A Comprehensive Survey on Reinforcement Learning-based Agentic Search: Foundations, Roles, Optimizations, Evaluations, and Applications
This survey from Lin et al. presents a comprehensive review of reinforcement learning-based agentic search systems, organizing the emerging field through three complementary analytical dimensions: what RL is for (functional roles), how RL is used (optimization strategies), and where RL is applied (scope of optimization). The authors categorize RL’s functional roles across five key areas: retrieval control (deciding when and how intensively to search), query optimization (conversational reformulation and retriever-aware adaptation), reasoning-retrieval integration (interleaving search with reasoning and managing context memory), multi-agent collaboration (planner-executor architectures and cooperative systems), and tool/knowledge integration (coordinating multi-modal tools and navigating structured knowledge bases). In terms of optimization strategies, the survey examines training regimes (cold-start initialization via supervised fine-tuning versus direct RL, simulation-based training), policy gradient algorithms (primarily PPO and GRPO variants), and reward design mechanisms. The scope of RL application spans agent-level optimization, module-level and step-level refinement, and system-level orchestration. The authors comprehensively review evaluation protocols across knowledge-intensive QA datasets, web-based search environments, multi-modal benchmarks, and domain-specific applications.
📚 https://arxiv.org/abs/2510.16724
👨🏽💻 https://github.com/ventr1c/Awesome-RL-based-Agentic-Search-Papers
[3] FACE: A General Framework for Mapping Collaborative Filtering Embeddings into LLM Tokens
This paper from Wang et al. introduces FACE (Framework for mApping Collaborative filtering Embeddings), an approach that bridges the semantic gap between collaborative filtering (CF) recommendation models and LLMs. The core challenge addressed is that LLMs, designed for natural language processing, cannot directly interpret the non-semantic latent embeddings produced by CF methods. FACE employs a two-stage solution: first, a vector-quantized disentangled representation mapping uses a multi-projector and transformer encoder to decompose entangled CF embeddings into concept-specific vectors, then applies residual quantization with a frozen LLM vocabulary codebook to convert continuous embeddings into discrete textual tokens called “descriptors.” Second, a contrastive learning alignment strategy ensures these descriptors maintain semantic consistency with corresponding textual information by aligning descriptor-generated embeddings with user/item summaries. This model-agnostic framework operates without fine-tuning the LLM, instead leveraging pre-trained token embeddings to achieve semantic interpretability.
📚 https://arxiv.org/abs/2510.15729
👨🏽💻 https://github.com/YixinRoll/FACE
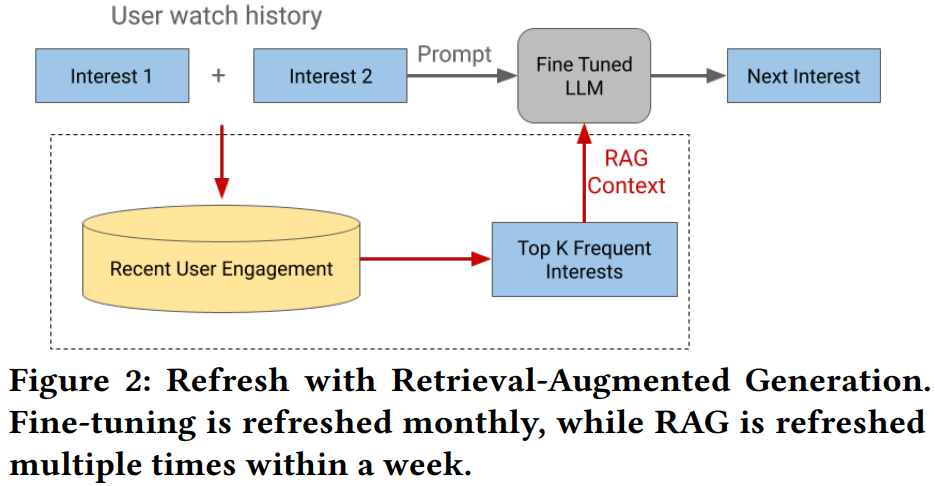
[4] Balancing Fine-tuning and RAG: A Hybrid Strategy for Dynamic LLM Recommendation Updates
This paper from Google addresses the challenge of maintaining up-to-date LLM-powered recommendation systems in dynamic environments where user interests and content constantly evolve. The authors conduct a comparative analysis of fine-tuning and RAG update strategies using a deployed user interest exploration system. Their analysis reveals that user interest transitions exhibit substantial monthly variability (mean Jaccard similarity of 0.17), demonstrating that static fine-tuned models quickly become outdated. While fine-tuning offers deep knowledge adaptation but incurs high computational costs and complexity, RAG provides agility and low-cost updates by incorporating recent user interaction data directly into prompts without modifying model parameters. The authors propose a hybrid strategy combining monthly fine-tuning for long-term adaptation with sub-weekly RAG updates (specifically instance-level, frequency-based retrieval of the top-1 most frequent next cluster) for capturing short-term dynamics. Live A/B experiments on a production system using Gemini 1.5 demonstrate that this hybrid approach yields statistically significant improvements in user satisfaction metrics. Offline evaluations confirm that regularly refreshed RAG mappings maintain higher hit rates and better alignment with evolving user behavior compared to static mappings, providing a practical and cost-effective framework for production-scale LLM recommendation systems.
📚 https://arxiv.org/abs/2510.20260
[5] Mixture of Experts Approaches in Dense Retrieval Tasks
This paper from the University of Milano-Bicocca investigates integrating Mixture-of-Experts (MoE) architectures into Dense Retrieval Models (DRMs) for information retrieval tasks. The authors propose SB-MOE, which adds a single MoE block after the final Transformer layer of a DRM rather than integrating MoE within each layer, reducing parameter overhead while maintaining efficiency. The approach employs multiple expert pairs (Feed-Forward Networks) selected by a learned gating function, with two variants using different pooling strategies: SB-MOETOP-1 (selecting the highest-weighted expert) and SB-MOEALL (weighted combination of all experts). Experiments across seven IR benchmarks and four base models (TinyBERT, BERT-Small, BERT-Base, Contriever) show that SB-MOE significantly enhances retrieval performance for lightweight models like TinyBERT and BERT-Small, while showing marginal gains for larger models. Zero-shot evaluation on 13 BEIR datasets demonstrates strong generalizability, particularly for lightweight DRMs. Hyperparameter analysis shows that 3-7 experts are typically activated during inference regardless of total expert count, indicating performance gains can be achieved without substantial computational overhead, making the approach especially suitable for resource-constrained environments where lightweight models benefit most from expert specialization.
📚 https://arxiv.org/abs/2510.15683
👨🏽💻 https://github.com/FaySokli/SB-MoE
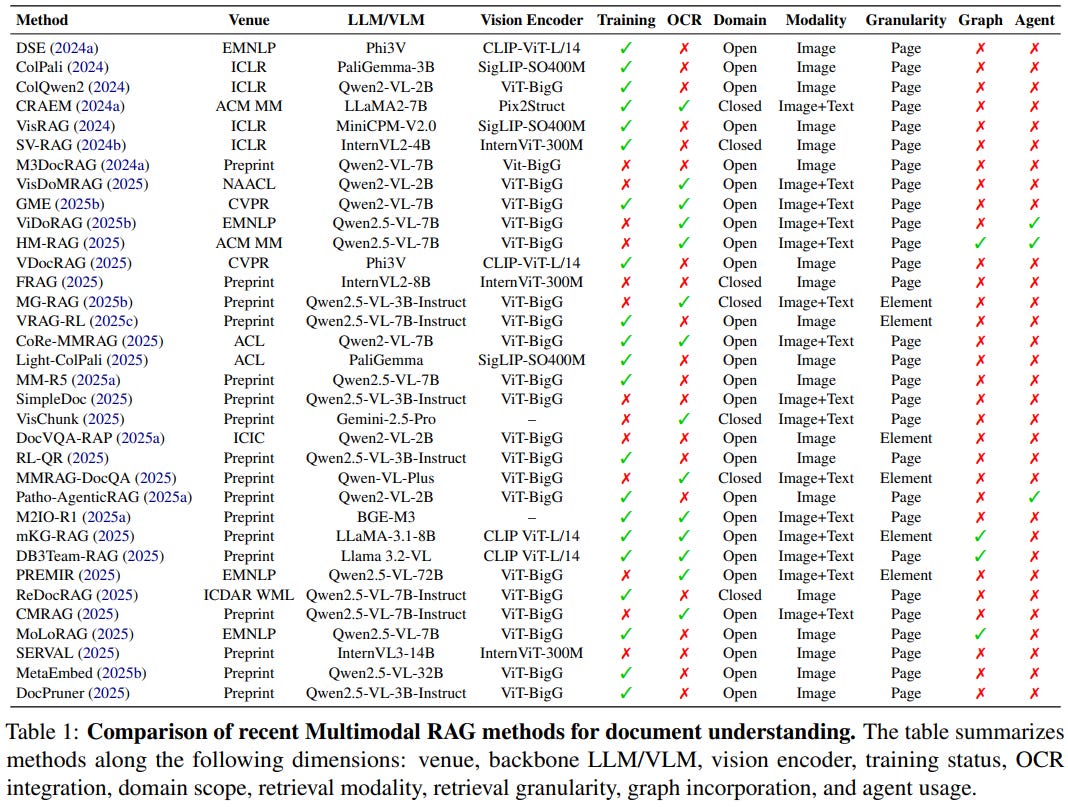
[6] Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding
This survey from Gao et al. examines Multimodal RAG for document understanding, addressing limitations of both OCR-based pipelines and native Multimodal Large Language Models (MLLMs) in handling visually rich documents containing text, tables, charts, and complex layouts. The authors propose a systematic taxonomy organizing methods by domain scope (open vs. closed), retrieval modality (image-only vs. image+text), and granularity (page-level vs. element-level), while analyzing hybrid enhancements through graph-based structures and multi-agent frameworks. The survey reveals that while early approaches relied on computationally expensive OCR extraction, recent vision-language models enable direct encoding of document pages as images, with state-of-the-art methods like ColPali, VisRAG, and M3DocRAG achieving significant efficiency gains. The analysis demonstrates that closed-domain multimodal RAG effectively handles extremely long documents by retrieving only relevant pages, mitigating context window limitations and hallucination risks, whereas open-domain approaches construct large-scale knowledge bases across document collections.
📚 https://arxiv.org/abs/2510.15253
[7] Structure-R1: Dynamically Leveraging Structural Knowledge in LLM Reasoning through Reinforcement Learning
This paper from Wu et al. introduces Structure-R1, a framework that enhances LLM reasoning on knowledge-intensive tasks by transforming retrieved documents into structured representations (like tables, knowledge graphs, or timelines) rather than processing raw text. The approach uses reinforcement learning with Group Relative Policy Optimization (GRPO) to train a policy that dynamically selects or generates task-specific structural formats during multi-step reasoning. A key innovation is the self-reward structural verification mechanism, which ensures generated structures are both correct and self-contained by having the model answer queries using only the structured representation, without access to original documents. Evaluated on seven benchmarks, Structure-R1 with a 7B-parameter backbone (Qwen2.5-7B-Instruct) achieves state-of-the-art performance among similarly-sized models and matches or exceeds larger models like GPT-4o-mini on several tasks. The framework operates under an open-world setting where it can generate novel structural formats beyond predefined schemas when needed, with theoretical analysis demonstrating that structured representations improve reasoning by increasing information density and reducing noise compared to fragmented plain text chunks.
📚 https://arxiv.org/abs/2510.15191
👨🏽💻 https://github.com/jlwu002/sr1
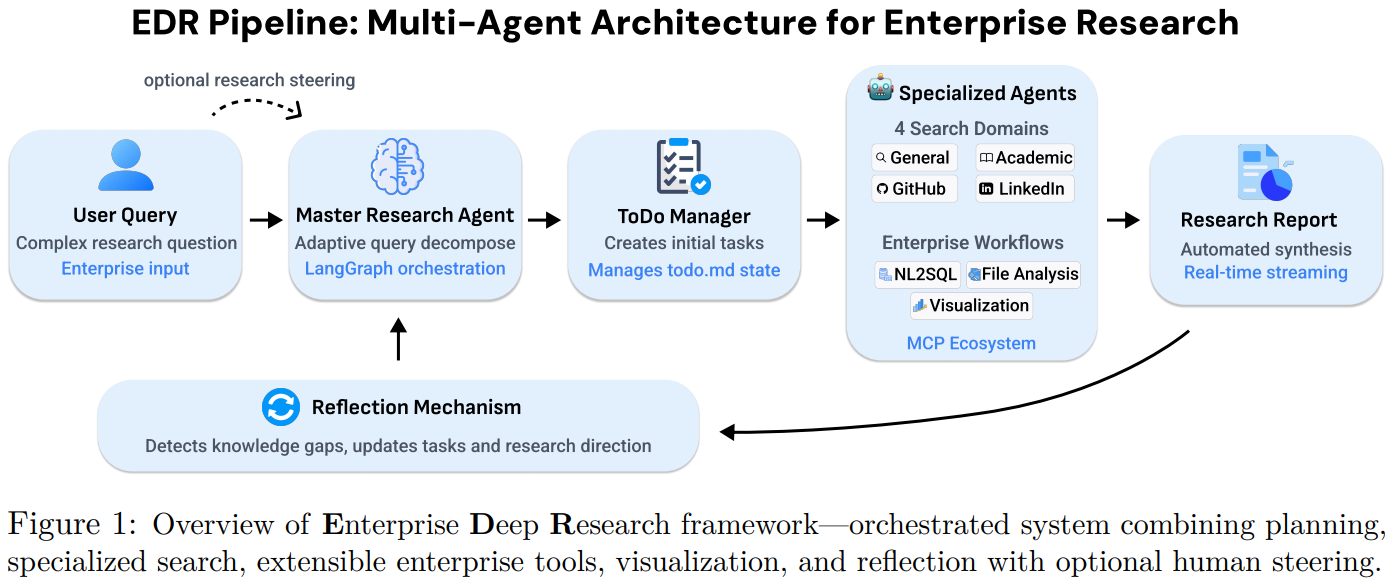
[8] Enterprise Deep Research: Steerable Multi-Agent Deep Research for Enterprise Analytics
This paper from Salesforce AI Research introduces Enterprise Deep Research (EDR), a transparent and steerable multi-agent framework designed to address limitations in enterprise analytics where opacity and inflexibility hinder practical deployment. EDR integrates five core components: (1) a Master Planning Agent that performs adaptive query decomposition and coordinates multi-agent execution, (2) four specialized search agents targeting general web content, academic literature, GitHub repositories, and LinkedIn profiles, (3) an extensible Model Context Protocol (MCP)-based tool ecosystem supporting NL2SQL translation, file analysis, and custom enterprise workflows, (4) a Visualization Agent for data-driven insights, and (5) a reflection mechanism that identifies knowledge gaps and enables optional human-in-the-loop steering through a todo-driven interface. Unlike existing systems that operate as black boxes with rigid execution plans, EDR implements “steerable context engineering” by exposing the agent’s internal planning state via a persistent todo.md file and allowing users to dynamically modify research direction through natural language steering inputs that are translated into task additions, cancellations, or priority adjustments.
📚 https://arxiv.org/abs/2510.17797
👨🏽💻 https://github.com/SalesforceAIResearch/enterprise-deep-research
🤗 https://huggingface.co/datasets/Salesforce/EDR-200
[9] WebSeer: Training Deeper Search Agents through Reinforcement Learning with Self-Reflection
This paper from Tsinghua University presents WebSeer, a search agent trained through reinforcement learning with self-reflection to handle complex multi-hop question answering tasks. The authors address three limitations in existing search agents: insufficient search depth (models prematurely stop searching), lack of spontaneous self-reflection mechanisms (no cross-verification or query reformulation), and neglect of real-world web scenarios. WebSeer employs a two-stage training framework combining supervised fine-tuning on self-reflective reasoning trajectories and Self-Reflective Reinforcement Learning (SRRL), which allows the model to submit and refine answers multiple times based on F1-score feedback. The system uses three tools: web search API, webpage reader, and code executor. Through rejection sampling, they construct training data with multi-turn reasoning that includes both correct and incorrect answer attempts, teaching the model to verify and refine its responses. Using a single 14B parameter model, WebSeer achieves state-of-the-art results on HotpotQA (72.3% accuracy) and SimpleQA (90.0% accuracy), demonstrating strong generalization to out-of-distribution datasets.
📚 https://arxiv.org/abs/2510.18798
👨🏽💻 https://github.com/99hgz/WebSeer
[10] Rethinking On-policy Optimization for Query Augmentation
This paper from Xu et al. presents a systematic comparison of prompt-based and reinforcement learning-based query augmentation methods for information retrieval, revealing that simple training-free approaches often match or exceed expensive RL-based methods. The authors compare DeepRetrieval (an RL method using PPO to train LLMs for query rewriting) against SPQE (Simple Pseudo-document Query Expansion, a zero-shot prompting baseline) across evidence-seeking, ad hoc, and tool retrieval tasks using both sparse (BM25) and dense retrievers. Their key finding shows that SPQE consistently achieves competitive or superior performance, particularly with powerful LLMs like GPT-4o-mini, while being computationally efficient and requiring no training data. Building on this insight, they propose OPQE (On-policy Pseudo-document Query Expansion), a hybrid method that applies RL optimization not to query rewriting but to pseudo-document generation, thereby combining prompting’s structured knowledge-rich output format with RL’s targeted optimization mechanism. OPQE achieves state-of-the-art results by starting with stronger initial rewards from pseudo-documents and fine-tuning through retrieval feedback, outperforming both standalone prompting and traditional RL-based rewriting across multiple benchmarks.
📚 https://arxiv.org/abs/2510.17139
👨🏽💻 https://github.com/BaleChen/RethinkQAug
I hope this weekly roundup of top papers has provided you with valuable insights and a glimpse into the exciting advancements taking place in the field. Remember to look deeper into the papers that pique your interest.
I also blog about Machine Learning, Deep Learning, MLOps, and Software Engineering domains. I explore diverse topics, such as Natural Language Processing, Large Language Models, Recommendation Systems, etc., and conduct in-depth analyses, drawing insights from the latest research papers.